On July 17-19, 2026, Megaladata took part in e-Logi Fest 2026, Armenia's leading international event dedicated to logistics, e-commerce, and supply chain innovation.
Features of Working With NULL in Megaladata


Empty values in data can create serious difficulties in processing. Using the NULL value allows you to avoid the uncertainty that arises when operating with them. Let's consider how to correctly process sets of such data.
NULL is a pseudovalue (marker, flag) in a table cell. It indicates that the cell is empty, i.e., does not contain any value, including a visually indistinguishable one, such as an empty string "" (a string of zero length).
The concept of NULL was originally introduced into the SQL language by Edgar Codd, the author of the rules underlying the construction of relational databases, in his groundbreaking paper "A Relational Model of Data for Large Shared Data Banks" in 1970. The fourth rule states that a relational DBMS (Database Management System) must provide full processing of unknown values, for which the concept of NULL was introduced. Its support, according to Codd, is a condition for the database to be relational.
Differentiating NULL from other values
Within the SQL standard, the NULL value is not equivalent to either 0 or the empty string "". However, some DBMSs, such as Oracle , deviate from this rule, considering NULL and the empty string equivalent. This may cause a certain logical contradiction, since the length of the empty string is 0, while the length of the pseudovalue remains undefined.
The main feature of NULL is that it is not equal to any value, not even itself (indeterminacy). Therefore, comparing NULL with any value using the operators greater than, less than, greater than or equal to, less than or equal to, equal to, or not equal to is meaningless, as is comparing with a non-existent value.
The result of such an operation will not be TRUE or FALSE, but a third logical value UNKNOWN. Thus, in the relational model using NULL, three-valued logic takes place.
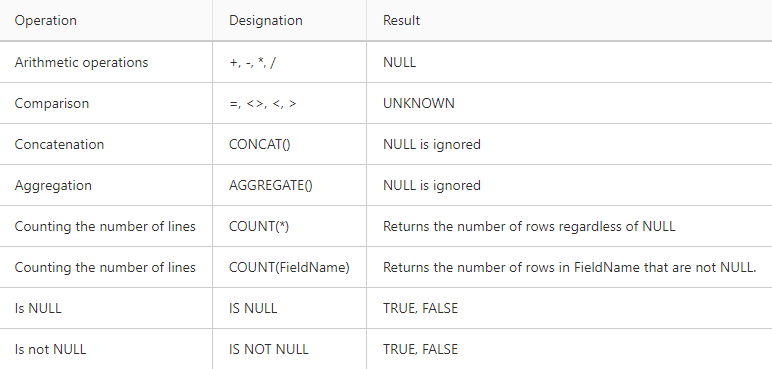
However, in relational DBMSs, it is possible to check whether the contents of a cell are a pseudovalue. This is done using the IS NULL function, which returns TRUE if the cell contains NULL and FALSE otherwise. The NOT NULL function, respectively, works the other way around.
During aggregation, NULL values are typically ignored. This is because including a NULL value in an aggregation operation often results in a NULL result. For example, when calculating the sum of a field containing values (4, 6, NULL, 3), the sum would be calculated as 4 + 6 = 10, then 10 + NULL = NULL, and finally NULL + 3 = NULL. Therefore, ignoring NULL values in aggregations helps to ensure accurate and meaningful results. When calculating the average for a set containing NULL values, the average is typically calculated over the non-NULL values. In the example above, the average would be calculated using only the values 4, 6, and 3, resulting in an average of (4 + 6 + 3) / 3 = 4.33.
If an aggregation is applied to a field that contains only a pseudovalue, the result will be NULL.
Another operation with NULL, the result of which will also be NULL, is merging the contents of cells. If one of the cells contains a pseudovalue, then the result will also be an empty value. To prevent this situation, use the CONCAT() function, which receives a list of arguments as input and replaces NULL values with empty strings.
Information about various operations with NULL is presented in the table.
The necessity of using NULL
The need to mark NULL in a specific way is due to the fact that working with it does not fit into the usual rules. For example, if you need to sum the values by a field that has an empty cell, the summation operation will be performed with one of the operands missing, resulting in an error.
If you put a flag or a marker of missing data in the empty cell and define a set of rules according to which such a "value" (NULL) should interact with other values, then the error can be avoided and the operation can be completed in some form. All operators and functions work with empty values, but the result may not be what the user would expect if there were no NULL value.
The question may arise: why can't we use 0 or an empty string where values are missing?
The thing is that 0 implies that the data is present, although the size of the value associated with it is zero (for example, a zero amount on an account or a zero stock balance). Confusing NULL with 0 may lead to an error in calculations: zero is still a number with which you can perform most arithmetic operations.
An empty string "" also cannot designate missing data either. It has a length (even though it is zero), which a missing value cannot have. With an empty string, you can perform any string operation and obtain a correct result. An empty string is not identical to an empty value.
Reasons for NULL in data
The causes of NULLs are usually related to gaps in data, the most common examples of which are:
- A skipped field. For example, a client filling out a questionnaire or an application does not enter some data.
- Human error when entering data. If the operator entered a value that does not match the format or data type of a screen form field, the value will not be saved, and the field will remain empty.
- Delay in receiving data. For example, the goods were shipped but were delayed in transit, so the arrival mark field may remain empty for some time.
- Performing operations on cells containing NULL. Arithmetic operations on cells, one of which contains NULL, will result in NULL.
Operating NULLs in Megaladata
When importing data and some other operations, empty cells may appear in Megaladata. The results of working with them may seem unexpected. This is due to the specific logic of NULL processing.
Visualization of NULL in Megaladata
One of the challenges with NULL values is their visual representation. In some applications, NULL values might be automatically displayed for empty cells, while in others, they may only appear when a specific option is activated. Some applications might not offer any visual indication of NULL values at all. This inconsistency in how NULL is displayed across different applications can make it difficult for users to accurately interpret data, often requiring them to learn the specific conventions of each program.
For example, some SQL tools automatically display NULL in a special way.
In Megaladata, when quickly viewing NULL in string type fields, it is displayed immediately. This is necessary so that the user can distinguish between a field with NULL and an empty string "". In order to see empty values in fields of all types, you need to go to the Visualizer options and select the Table visualizer. Click on the corresponding toolbar button (highlighted in red):
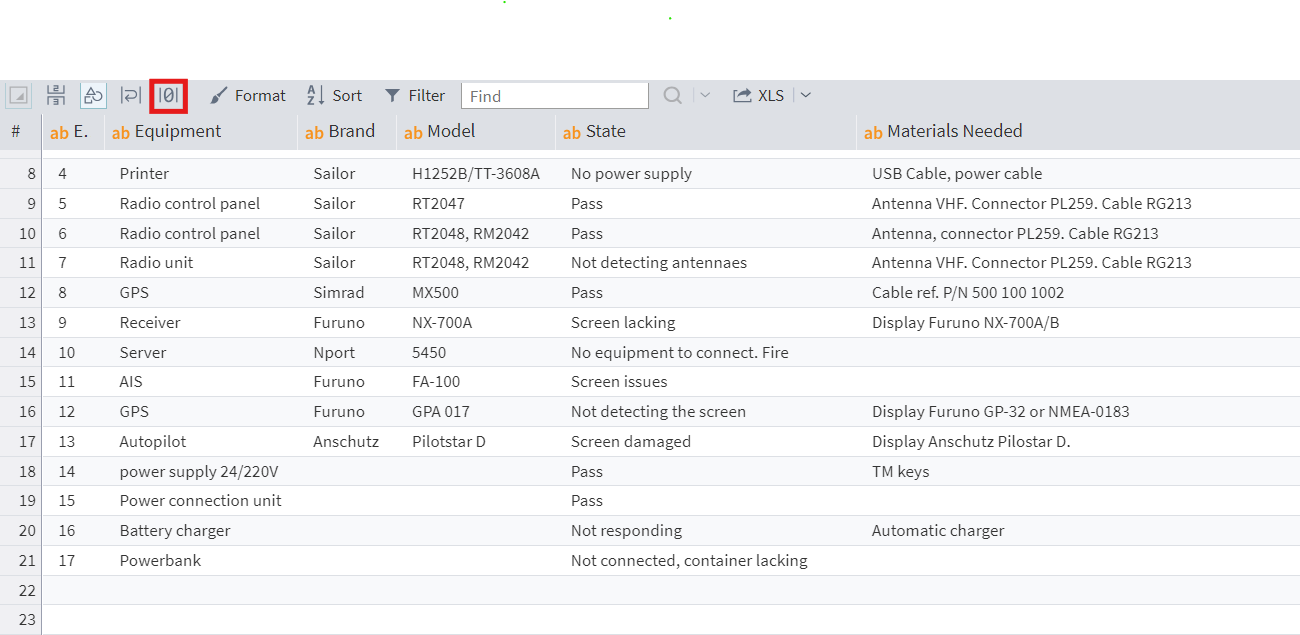
Figure 1: Automatically set NULL in Megaladata
The cells which have empty values will be indicated with "null":
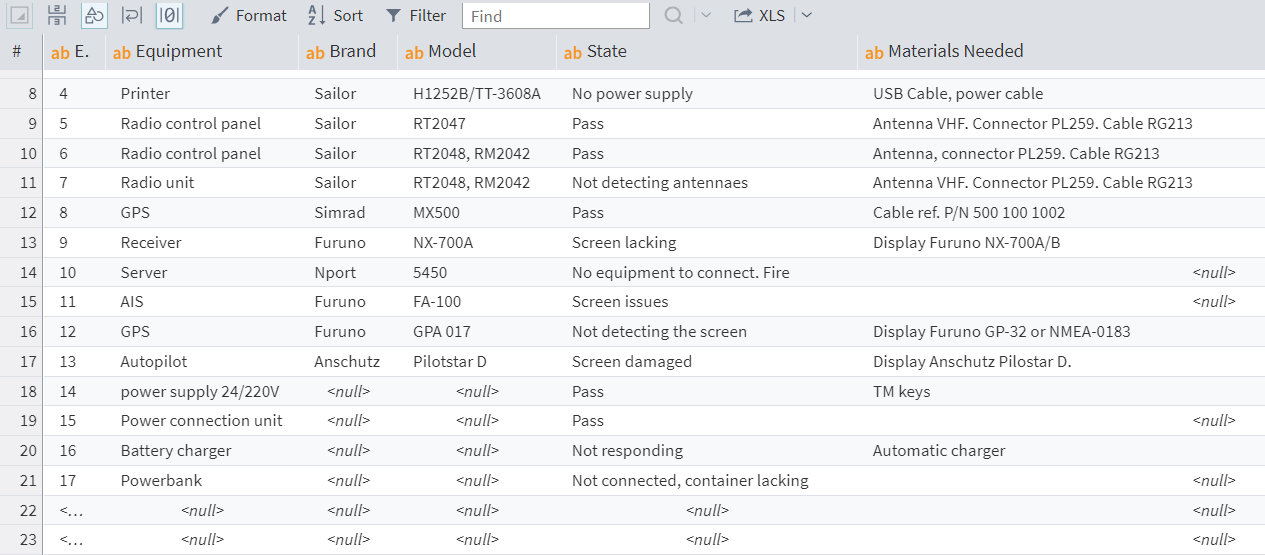
Figure 2: Displaying NULLs
In addition, you can see the presence of NULLs in the table and determine their number using the Statistics visualizer or the Data Quality visualizer.
Checking for NULL values in data
In Megaladata, you can check whether a cell value is NULL. This is done using the IsNull() function, which returns TRUE if the cell contains NULL and FALSE otherwise.
Let's compose the expression in the Calculator node:
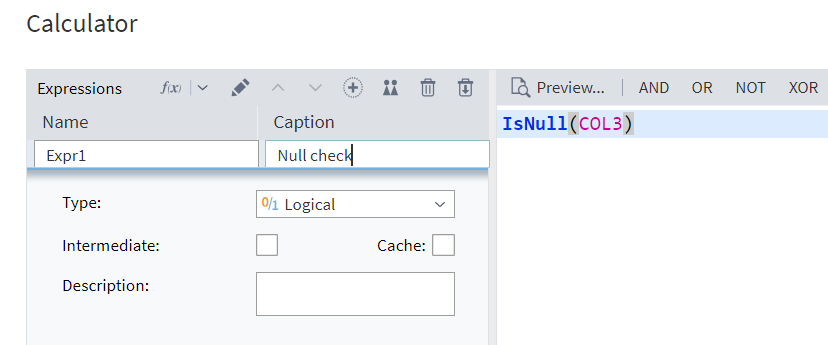
Figure 3: Using the IsNull() function
The result will be as follows:
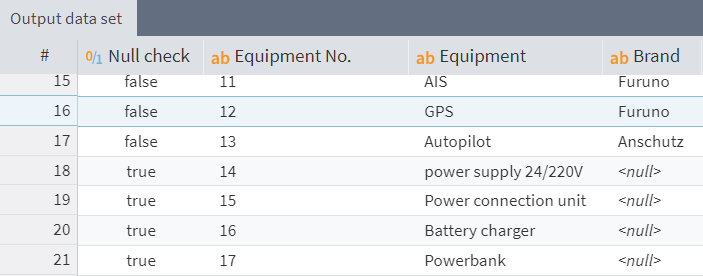
Figure 4: Result of the IsNull() function
The function can be specified not only for individual fields; but also for expressions or calculation results.
Arithmetic operations with NULL data
When performing arithmetic operations with fields containing NULL values, one must be careful not to get unintended results.
All sums of NULL cells result in NULL. This cumulative effect calls into question the ability to sum cells with NULL values.
However, this problem can be solved using the NVL() function. It returns the value of an expression which is not NULL, and allows users to set their own values otherwise.
Filtering data
Another frequently used operation when working with data is filtering. In Megaladata, it is performed using the Row Filter component. The question arises: how will NULL values be handled when checking filter conditions? Will NULL values be considered satisfying or not satisfying the filter condition?
NULL values in the filtered field are included in the subset of records that do not satisfy the filter condition. This is because NULL is not equal to (and therefore cannot be greater than or less than) any value.
This can create a curious situation: if you change the sign in the condition to the opposite, the subsets of records that satisfy and do not satisfy the condition will swap places. However, this is only true for records where the field by which the filter is performed does not contain NULLs. The records with NULLs will still be considered as not satisfying the filter condition.
To get a dataset that does not contain pseudovalues, you can use the following condition:
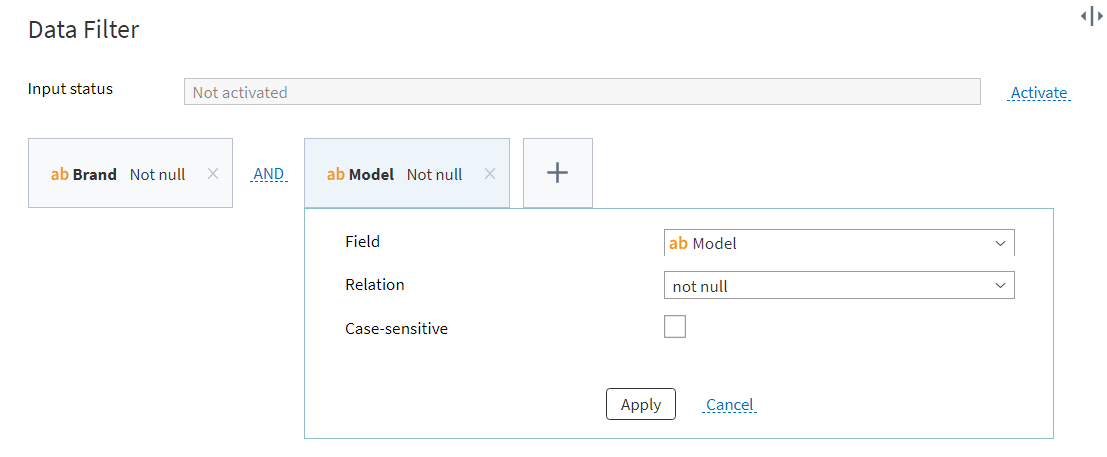
Figure 5: Filtering data
The result will be data that does not contain NULL values:
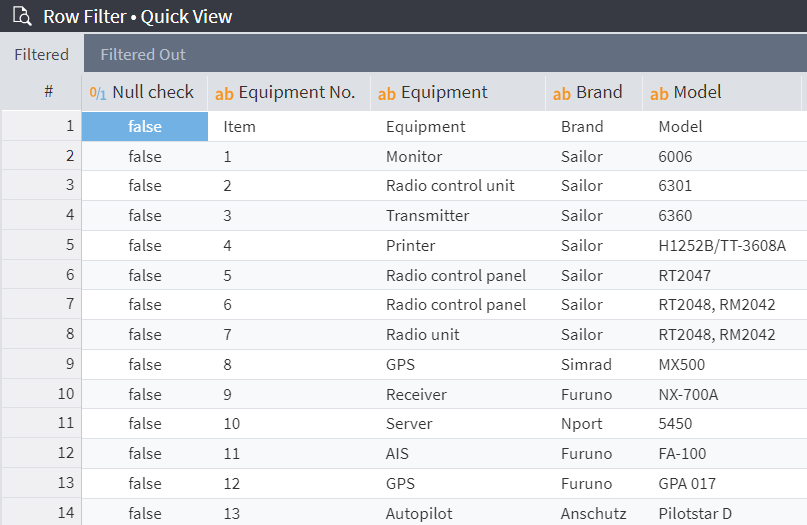
Figure 6: Data without NULL values
Sorting data
The Sort component handles empty values in a specific way. When sorting in ascending order, NULL values are placed first, before all other values. Pseudovalues are usually considered to be the minimum (or "less than" all other values). Accordingly, when sorting in descending order, NULL values will be placed last, after all other values.
Replacing values with NULL
While processing your dataset, you may sometimes encounter extreme or dummy values, that are not practical to work with in any form — it is better to process such a cell as empty than with what it contains.
In Megaladata, it is easy to replace such values in Calculator, using the IF function:
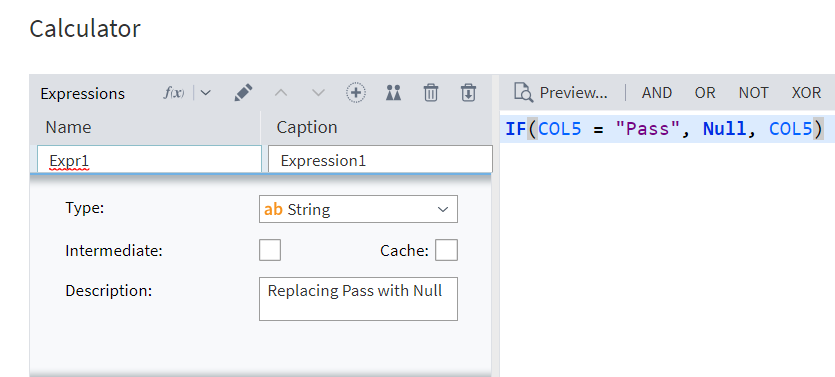
Figure 7: Expression for the NULL() function
Instead of the dummy values, we will have NULLs that can be handled later during data cleaning:
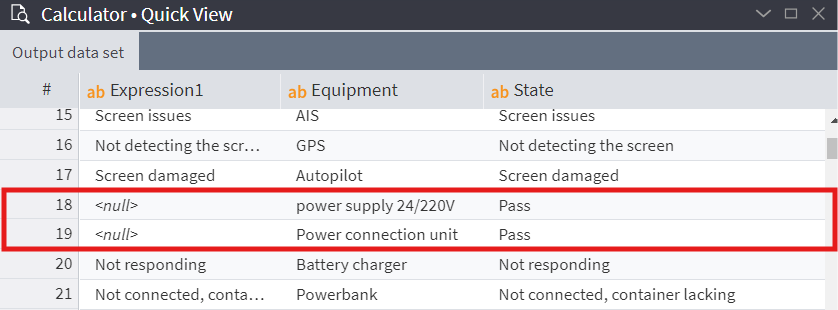
Figure 8: NULLs replaced
Data upload
The results of exporting tables with NULL values may vary, depending on where the data is exported to.
For example, when exporting a table from Megaladata to Excel, NULL values are not shown the target table.
This is because Excel is not a DBMS, and NULL has a different purpose in it. Excel does have empty cells, and their use in formulas leads to undefined results. In this case, NULL is displayed in the cell containing the formula. Thus, in Excel NULL is not used as a flag for the absence of data in the cell, but rather, as an indicator of an undefined value of a formula in which one of the operands is an empty cell.
Unlike Excel, when exporting to a csv file, the user is explicitly asked to select the type of indicator that indicates an empty cell. There are three options: "NULL", "null", or "?". It's important to note: since a text file is not a database file, NULL loses its meaning as understood in SQL. Pseudovalues and the rules for working with them are not regulated by the SQL standard, as in the case of DBMS, but are determined by the developer of a specific application.
Conclusion
The rules for working with NULL values depend on the software used, and the behavior of other applications may differ from the logic implemented by Megaladata. For correct processing, we recommended referring to the official documentation. Although using NULL values allows you to solve the problem of gaps in data to a certain extent, the way how applications work with this value type always requires attention and investigation.
See also

Megaladata at e-Logi Fest 2026

How Low-Code is evolving ETL
In 2026, you cannot scroll LinkedIn for five minutes without finding a post declaring "ETL is dead, ELT and AI have replaced it." It sounds compelling. It is also wrong.

Megaladata at Plug and Play Armenia Batch 3 Expo
On July 9, 2026, Megaladata took part in the Plug and Play Armenia Batch 3 Expo, the graduation event closing out the three-month International Pre-Acceleration Program in Armenia.
About Megaladata
Megaladata is a low code platform for advanced analytics
A solution for a wide range of business problems that require processing large volumes of data, implementing complex logic, and applying machine learning methods.
GET STARTED!
It's free