





On July 17-19, 2026, Megaladata took part in e-Logi Fest 2026, Armenia's leading international event dedicated to logistics, e-commerce, and supply chain innovation.
Low-Code Analytics at Top Speed
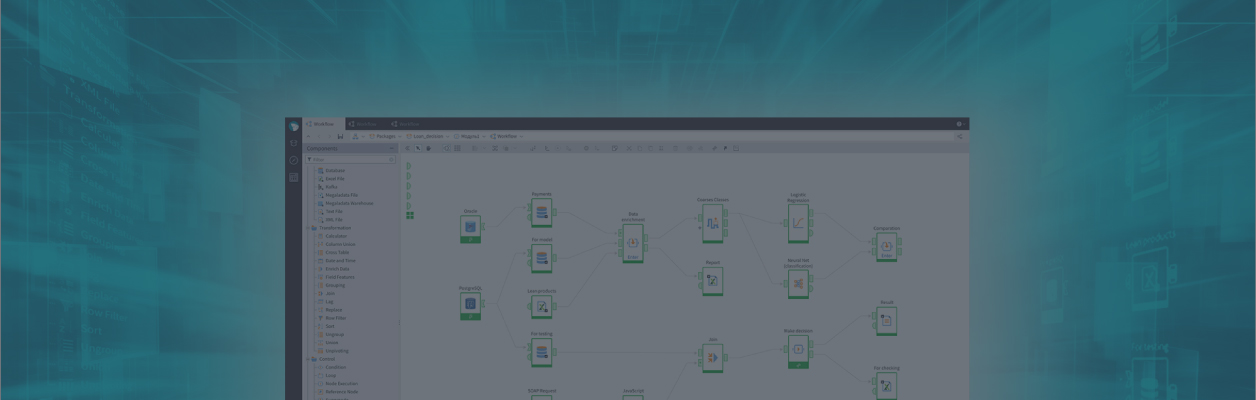

The Megaladata platform employs methods that ensure high-speed processing, efficient memory use, and easy scaling. Let's take a deeper look at what enables the platform's high performance and how Megaladata compares to the world's most popular low-code analytical platforms (based on test results).
Experts give various opinions concerning different data analysis technologies. Some prefer coding, while others advocate low-code/no-code techniques. Both sides offer compelling arguments to support their view.
The truth is that such preferences depend on habit and experience and are largely subjective. What one considers an advantage, the other calls a drawback. However, when it comes to performance, all arguments die away as no one would choose a lower processing speed.
Everyone hates waiting. That's why speed is a key factor when choosing a product. But high productivity shouldn't come at the cost of complicated setup. Ideally, it should work with minimal configuration, or even no setup at all.
Principles of Performance Optimization:
- Focus on System-Level Performance.
- Optimize Frequently Used Elements.
- Align with Hardware Capabilities.
- Identify Root Causes of Slowdowns.
Another important concept is to solve any task using the minimum possible number of applications, that is, having as few integration points as possible.
It can be compared to a highway, where top speed is possible, but only until there is a poor stretch. Here, the speed of traffic immediately drops. The slow-down section limits the actual speed on the road. Integration points are like bad stretches between highways.

Figure 1. Integrations
There is no way to avoid integration altogether, as we need to import the data from some source and export the results elsewhere. However, the more tools, platforms, and environments we use to transfer the data, the more productivity we lose. Integration consumes resources and time but creates no value for a user.
Guarantee of Efficiency
Megaladata is one of the world's fastest low-code platforms for advanced data analytics. Such a result is unachievable through some single technological solution. It is a complex and challenging task of optimization at all levels.
The main factors that contribute to the superior performance of Megaladata are:
- Architecture of the platform
- Processing Algorithms
- Visualization Techniques
- Use of CPUs, Memory, and Discs
- Managing Data Sources and Destinations
- Integration of the Platform's Components
When any of these points lack proper attention, building a high-performance system is impossible, as this point will become a bottleneck. Thus, let's examine each factor that impacts the operation speed in more detail.
Architecture of the Platform
The secret to Megaladata's high performance lies in its architecture, namely, the specific way memory is employed.
Big data often bumps against RAM limitations, especially for in-memory systems that prioritize speed by performing all the operations in the internal memory. Being a system of such type, Megaladata addresses this challenge by employing a range if techniques to minimise memory usage:
- Using Typed Data for Operations
- Storing Only Unique Values in RAM
- Employing Lazy Evaluation.
Lazy evaluation significantly reduces memory requirements: Instead of storing data in every workflow node, it's only stored in the highlighted nodes. This can be a huge advantage considering that typical workflows have tens or even hundreds of nodes.
The developers of Megaladata took lazy evaluation a step further by optimizing it for even greater efficiency:

Figure 2. Employing lazy evaluation
Let us draw an analogy to explain the idea of such optimization: Imagine that we search for a particular person, say, John. We need to know if John is present.
Before: We send a call to a group of people. Each one is asked: "Are you John?" If the answer is no, the person addresses the one next to them. If yes, questioning stops, and people start sending a message back down the chain: "John is here." Similarly, in Megaladata, it would be a sequence where a request passes from one node to the next until it encounters the source. As soon as it happens, the values are sent to the node that requested the data, passing the whole workflow on its way.
After: We ask just once if John is there, and John answers immediately. That is, the readers first determine where the source data is located, and then this location information is sent to the node requesting the data. Then, the data is passed directly from node to node, not involving the chain of intermediate handlers.
Another notable feature embedded into the platform's architecture is parallel computing 'out-of-the-box" and asynchronous user interface.
Parallelization support is essential for achieving high processing speed. While modern processors have more cores, in too many systems and programming languages utilizing them effectively often requires specialized knowledge and complex workarounds.
In Megaladata, any workflow that can be executed in parallel will be executed this way by default. This means users don't have to perform extra actions.
Finally, Megaladata employs one more technology, the asynchronous user interface. It doesn't affect processing time and, thus, doesn't directly contribute to the increase in speed. However, it makes the system more responsive and convenient to use. Long computations do not block the user interface; the analyst can switch to other tasks. This improves overall workflow efficiency and creates a perception of faster performance.

Figure 3. Asynchronous user interface
Processing Algorithms
Carl Sagan once said, "If you wish to make an apple pie from scratch, you must first invent the universe." As developers, we prioritize efficiency and avoid wasting time by utilizing existing, well-tested libraries whenever possible.
For writing Megaladata, we employed fast modern-day low-level libraries:
- LIBLINEAR — training logistic regression models.
- Intel MKL — matrix operations and linear algebra problems.
- fast_float — converting strings into real numbers.
- ALGLIB — statistical computations, neural network training.
The list could be continued. We test the performance of the libraries and choose the fastest available options. If we don't find a quick and high-quality library, the Megaladata programmers create new modules for our purposes. The company's team of professionals has developed many algorithms - see some examples below:
- Parallelization in Index Construction (Join and Enrich data).
- Approximation Computations in Training Machine Learning Models.
- Choosing Neural Network Hyperparameters.
- Downsampling Algorithms for Diagrams.
- Multidimensional Computations in Cubes.
Data Caching
Lazy evaluation prioritizes efficient RAM usage and typically does not influence the processing speed. However, caching the calculated data can be beneficial in certain scenarios especially when complex formulas are used or when the data calculated in one node is needed in many other nodes of your workflow. In these cases, caching becomes the better choice because it significantly speeds up data processing, even though it uses more RAM.
Many caching options are available in Megaladata, such as caching the entire dataset or specific columns only. You can also choose to cache data when activating a specific node or when the data is accessed. This flexibility allows you to find a balance between processing speed and memory usage.
Data Exchange Protocol
One of the most common bottlenecks in many analytical platforms is client-to-server data exchange. This becomes especially critical when working with datasets containing hundreds of millions or even billions of records.
To address this challenge and ensure high performance, Megaladata implements its own Remote Procedure Call (RPC) specifically designed for efficient data transfer between client and server. Its main functions are:
- Elimination of All Intermediary Layers
- Binary Data Transfer (to reduce the amount of information transmitted and minimize serialization loss)
- Batch Communication, Combining Small Requests into Bigger Blocks.
- Asynchronous Exchange.
Visualization
While working in a browser, the client-side of a visualizer retrieves data from the server-side for visualization. Since samples can be very large, it's more efficient to transfer only a specific portion. This can be achieved by transmitting the information in smaller segments (windowing) or by applying downsampling on the server to reduce the data size while preserving the sample's statistical properties.

Figure 4. Downsampling
For instance, to display a million-record table, the server sends to the client only the part of the sample seen on the user screen, along with a few records before and after that segment. When the user scrolls the table, new data is uploaded to correspond to the moving window. As a result, the interface is more responsive, and the requirements for the amount of transferred data are lower.
Use of CPUs, Memory, and Discs
The need for effective multithreading transparent to users led us to the development of our own scheme:
- Forming our thread pool.
- Monitoring CPU utilization to add a thread if any processor is under-used.
- Release of threads if they are not used.
- Sequential execution of tasks when parallelism is redundant.
Megaladata uses a resource manager to monitor CPU utilization. When Megaladata detects resource underutilization, for example, complex operations in a loop block with sufficient threads but slow data transmission, the system automatically starts a new thread.
These manoeuvres allow Megaladata to use available resources more efficiently, resulting in faster processing. Once the data is calculated and sent to the output, the system moves on to process another block.
Multiprocessor systems support is included in the operations with strings. For example, in the filtering process, strings are compared using a special function that denies atomic operations for accessing shared memory. It blocks the flow for all the processor cores. Due to such blocking, the system executes just one thread even if there are many cores. As a result, the filtering speed on multicore servers increases by about 20%.
Managing Data Sources and Destinations
In this area, we also have some nontrivial solutions. Here's the key: When a database is accessed via one connector, the requests are usually handled consequently rather than in parallel. The number of request processing threads is directly tied to the number of connectors.
Upon accessing a database management system, Megaladata creates a connection factory to enable a higher degree of parallelization. Additionally, connectors are cached in memory whenever possible so as not to waste time reconnecting.
The Megaladata developers have managed to optimize import from slower sources (CSV, xlsx):
- String data cached upon reading.
- Wyhash (the fastest quality hash function, as of 2019) employed. It is an algorithm optimized to fit modern CPUs.
- Comparison of strings in wyhash corresponds to comparing pointers, one of the fastest processor operations.
- The hash table size is chosen to fit in the cache memory and ensure maximal performance.
All this optimization results in a slightly slower import but less memory consumption and faster execution of the other nodes of the workflow.
Optimization of the Megaladata Data File Format
The next step we took to increase operating speed was optimizing the Megaladata Data File format. To do this, we replaced the compression algorithm LZ0 with LZ4, adding the checksum computation.
In the process of export, unique strings are stored in the file, and the writing speed falls. As a result, the file size increases by about 10%, but reading becomes 39% faster. Also, RAM consumption during import is lower.
Integration of the Platform's Components
Typically, the Integrator and the Server communicate via TCP. However, for single-machine deployments, a Unix domain socket can be employed. This results in approximately a 15% performance boost.
Another significant aspect is the enhanced performance of the Python node, which acts as a bridge between Megaladata and external systems
To achieve parallelism, unsupported by default in Python, the process involves uploading analysis samples to files. Multiple interpreters are then launched to process these samples. The results are subsequently written as binary column-store files before being uploaded back to the Python node. This entire process remains transparent to the analyst, yet significantly accelerates data exchange between the Python node and other workflow components.
Comparison to Competitors
The most compelling evidence of Megaladata's optimization effectiveness is how our platform compares to other leading products in the field. We have picked out the competitors whose software occupies leading positions in the global market, according to Gartner:
- Alteryx.
- Dataiku.
- KNIME.
- Pentaho.
- RapidMiner.
We have chosen to compare the desktop editions. A fair comparison of cloud-based products necessitates ensuring similar infrastructure, which is impractical. All these applications are publicly available. Anyone interested can download them free of charge and conduct their own independent evaluation.
We focussed on three key criteria for comparison:
- Task Execution Time
- RAM Usage
- CPU Utilization
To facilitate the comparison, we assigned three tasks that each system could complete.
Task 1. A simple processing workflow
Creating a sales report; performing ABC and XYZ analysis with minimum settings. This task tests the performance of basic operations with data:
- Import of CSV files.
- Datasets join.
- Calculation by formulas.
- Grouping and sorting.
- Calculation of simple statistics.
- Binning.
- Export of CSV files.
We have picked such a task based on the fact that, in real life, analysts deal with these operations almost daily.
Megaladata employs supernodes which are special nodes containing other workflow nodes. These supernodes don't alter the overall logic, and all tools within them perform identical operations.
Test computer configuration: AMD Ryzen 5 5600G 3.9 GHz (6 cores, 12 threads), DDR 32 Gb 3200 MHz, SSD ADATA SP90.
Analyzed data:
- CSV file – 49.7 million records (7.1 Gb).
- CSV file – 2.2 million records (364 Mb).
Results of the first task:
As RapidMiner requires uploading data to a repository before processing, from here on we will add this time to the computation time.

Task 1
Task 2. A larger amount of data, more computations
Upon a single data upload, the system has to handle three copies of simple workflows we created earlier to demonstrate parallel processing capabilities. This scenario simulates a situation when large data amounts are imported once from several sources and then undergo computations in many workflows of medium complexity.
Analyzed data:
- CSV file – 49.7 million records (7.1 Gb).
- CSV file – 31.0 million records (7.4 Gb).

Task 2
Task 3. High-loaded processing
All processing stages are repeated three times: from data import to results upload. Not only the computation block, but the whole process must be performed simultaneously — a typical case for high-loaded systems.
Analyzed data:
- 4 * CSV file – 49.7 million records (7.1 Gb).
- 4 * CSV file – 31.0 million records (7.4 Gb).
All the processing, including import, is repeated.

Task 3
See also

Megaladata at e-Logi Fest 2026

How Low-Code is evolving ETL
In 2026, you cannot scroll LinkedIn for five minutes without finding a post declaring "ETL is dead, ELT and AI have replaced it." It sounds compelling. It is also wrong.

Megaladata at Plug and Play Armenia Batch 3 Expo
On July 9, 2026, Megaladata took part in the Plug and Play Armenia Batch 3 Expo, the graduation event closing out the three-month International Pre-Acceleration Program in Armenia.
About Megaladata
Megaladata is a low code platform for advanced analytics
A solution for a wide range of business problems that require processing large volumes of data, implementing complex logic, and applying machine learning methods.
GET STARTED!
It's free