On July 17-19, 2026, Megaladata took part in e-Logi Fest 2026, Armenia's leading international event dedicated to logistics, e-commerce, and supply chain innovation.
How to Resolve Data Quality Issues


Data quality is essential for effective decision-making. Organizations rely more on data-driven strategies to improve outcomes, yet many overlook the critical importance of accurate, complete, and reliable information. We will investigate the main problems affecting data quality and how these issues can prevent project success. This article will also propose strategies for improving data quality using Megaladata's components and visualisers.
You can have all of the fancy tools, but if your data quality is not good, you’re nowhere. —Veda Bawo (Data, Risk & Control at Silicon Valley Bank)
Most common data quality issues
Data quality issues are a major obstacle to project completion. Inaccurate or misleading information can lead to flawed analysis and poor decision-making.
Missing data causes issues not only because the data can be non-representative of the actual population’s information, but also because many algorithms do not work with missing data. Most algorithms in Scikit-learn, for instance, are still unable to deal with data containing empty values. We can use Imputation to fill in the missing entries of a feature with a specific value. This can be, for instance, the mean value of a column, its median, zero or more complex approaches, using Machine Learning algorithms.
Duplicate data refers to records in a database that are exact or partial copies of other entries. It most often occurs when transferring data between systems. The most common occurrence is a complete carbon copy of a record, but partial duplicates are also common. For example, records might share the same name, email, phone number, or address, but have other non-matching data. If not addressed, duplicate records can be harmful to your business. Any reports generated from such data will be inaccurate, so businesses cannot rely on them to make sound decisions.
Outliers are data points that differ significantly from the majority of observations. They may be the result of experimental errors, data entry mistakes, or even true natural deviations. If left unchecked, outliers can have an outsized effect on analysis. Even a few outliers can skew descriptive statistics like averages and standard deviations, influence correlation coefficients, and distort the training of machine learning models.
Noise is inaccurate or irrelevant information that contaminates datasets, hindering data analysis and interpretation. It can originate from various sources including hardware malfunctions, software bugs, human error, or unstructured data formats. This type of data not only consumes unnecessary storage space but also distorts results if not properly addressed.
Megaladata visualizers: Discover and assess quality issues
Visualizers in Megaladata are tools that offer users a convenient way to view data:
Statistics visualizer is a tool for exploring data distribution. It displays data fields and statistical indicators in a table format, allowing users to customize views and analyze specific metrics. Key features include histograms, box plots, and summary statistics. By understanding data characteristics through visualization, users can improve data quality by identifying anomalies, outliers, and patterns, leading to better decision-making.
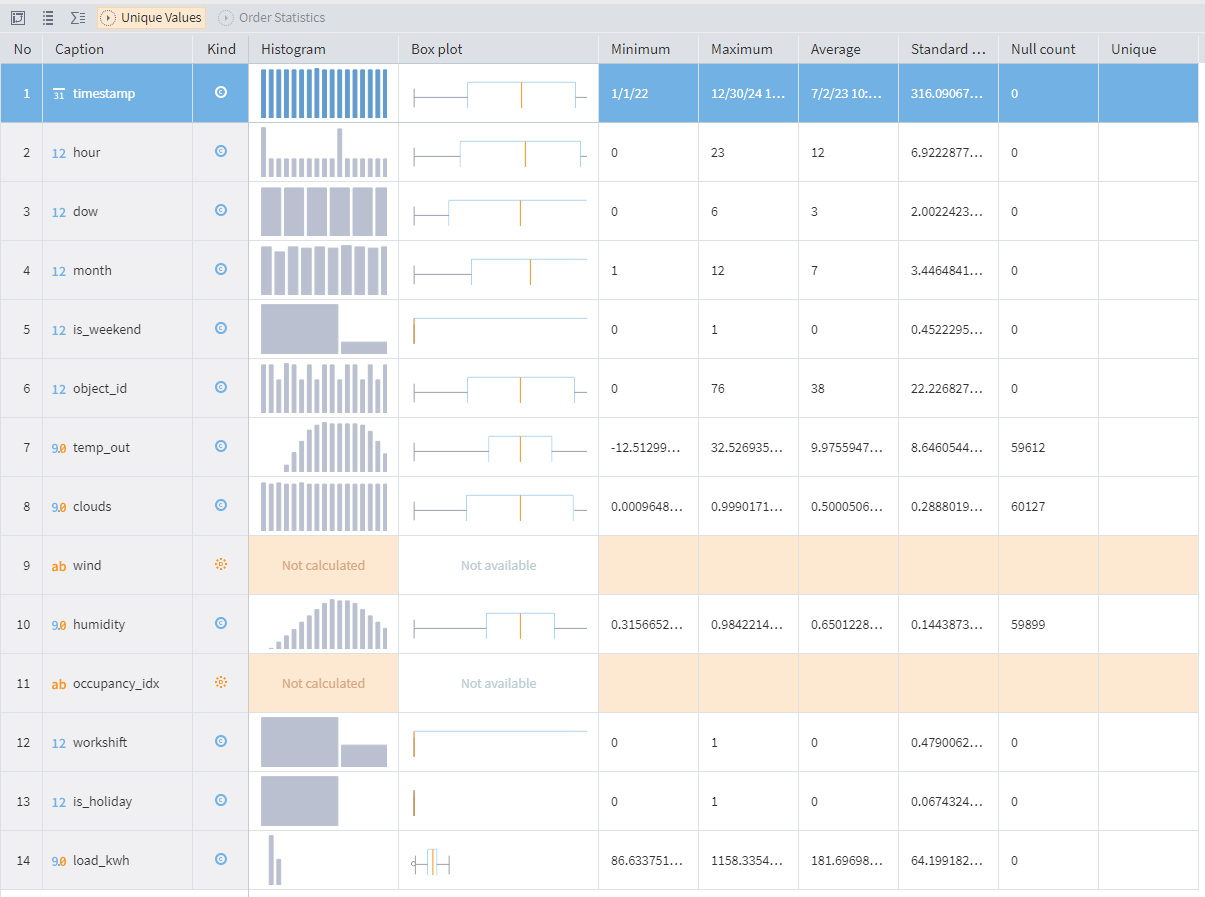
Statistics visualizer in Megaladata
Data Quality visualizer assesses data quality for each field, providing summaries, customizable metrics, and detailed exploration tools. Users can identify issues, view dataset characteristics, and export reports to aid data analysis.
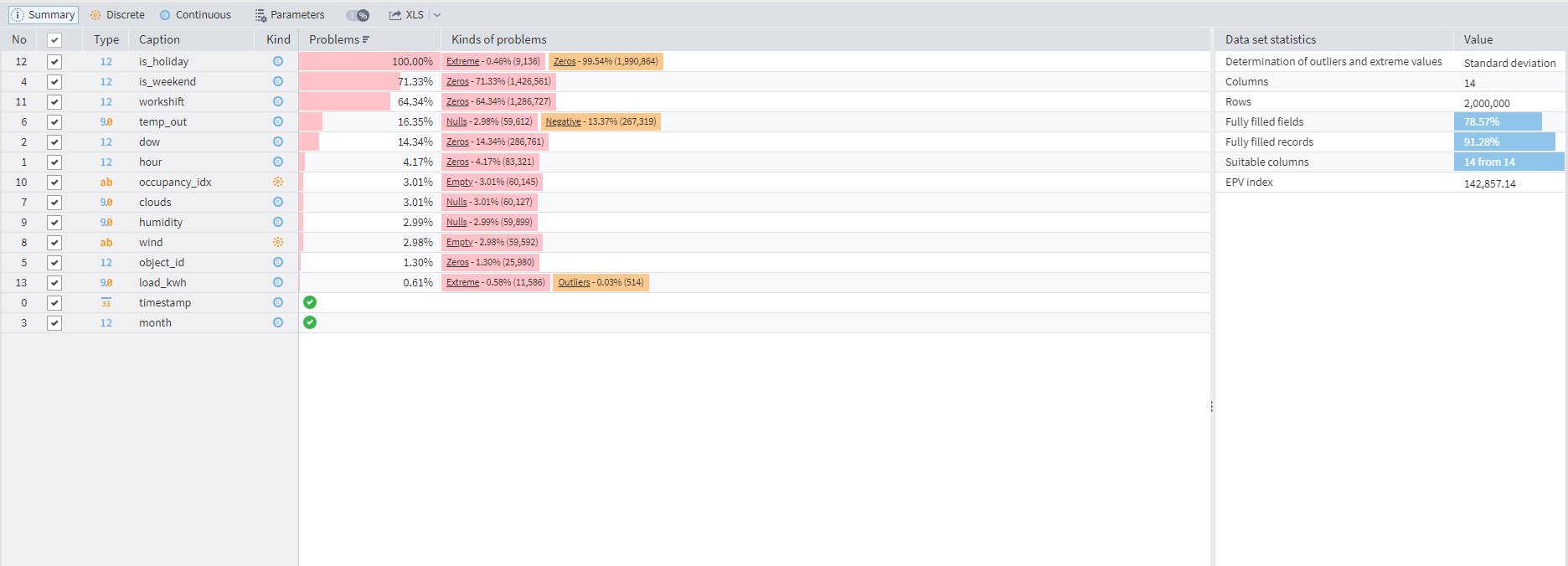
Data quality visualizer
Megaladata provides data cleaning and preprocessing tools. These tools enhance data quality by identifying and addressing issues such as duplicates, missing values, outliers, and noise. By utilizing the following components, users can improve the reliability and accuracy of their data analysis:
Duplicates and Contradictions: The component identifies and displays duplicate and inconsistent records within a dataset. Its interface includes tools for data display control and navigation, while the main table presents detailed information about the detected issues.
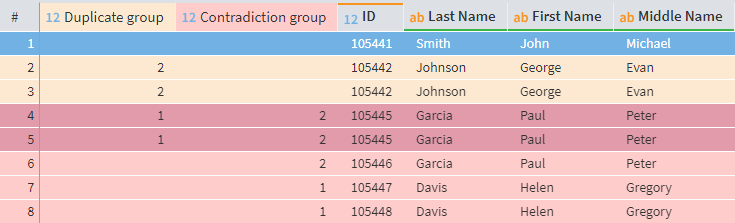
Duplicates and contradictions component
Imputation: This Megaladata component automatically fills in missing data in a dataset. Users can select imputation methods for each column, considering data type and order. Options include replacing nulls with averages, medians, or most frequent values, interpolating missing points, or leaving/deleting null data. The component can handle ordered data and allows setting a maximum percentage of nulls for imputation.
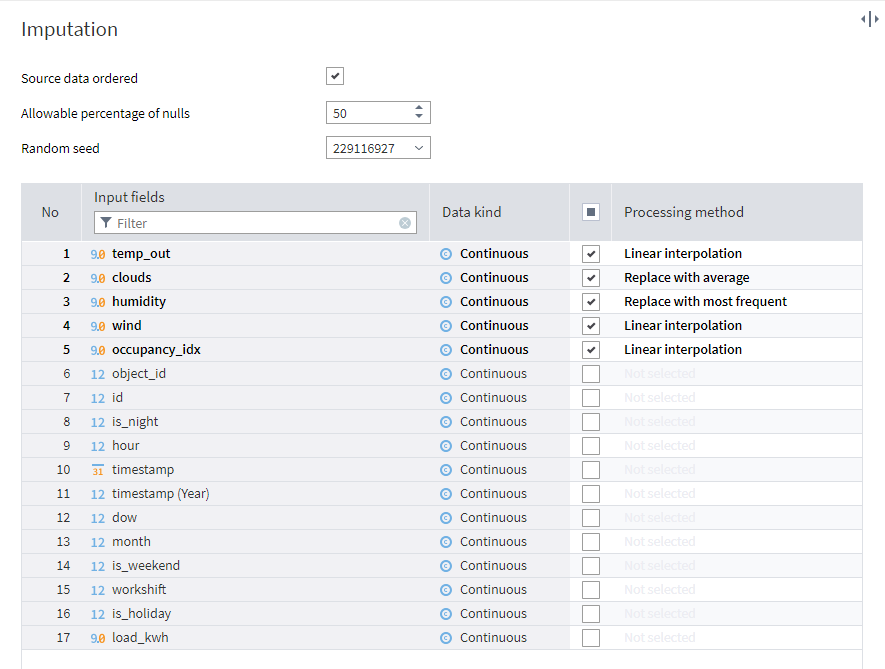
Imputation set up wizard
Eliminate Outliers: Use this component to automatically remove outliers and extreme values from your datasets. After you define outlier criteria, the component applies various processing methods based on data characteristics. Output includes the cleaned dataset and tables of detected anomalies.
Handling outliers
Smoothing is a tool to smooth out noisy data and identify trends. It uses either Hodrick–Prescott filtering or wavelet methods (Daubechies, Coiflet, or CDF 9/7) to create smoother versions of your data. You can choose which columns to smooth and adjust settings for each technique.
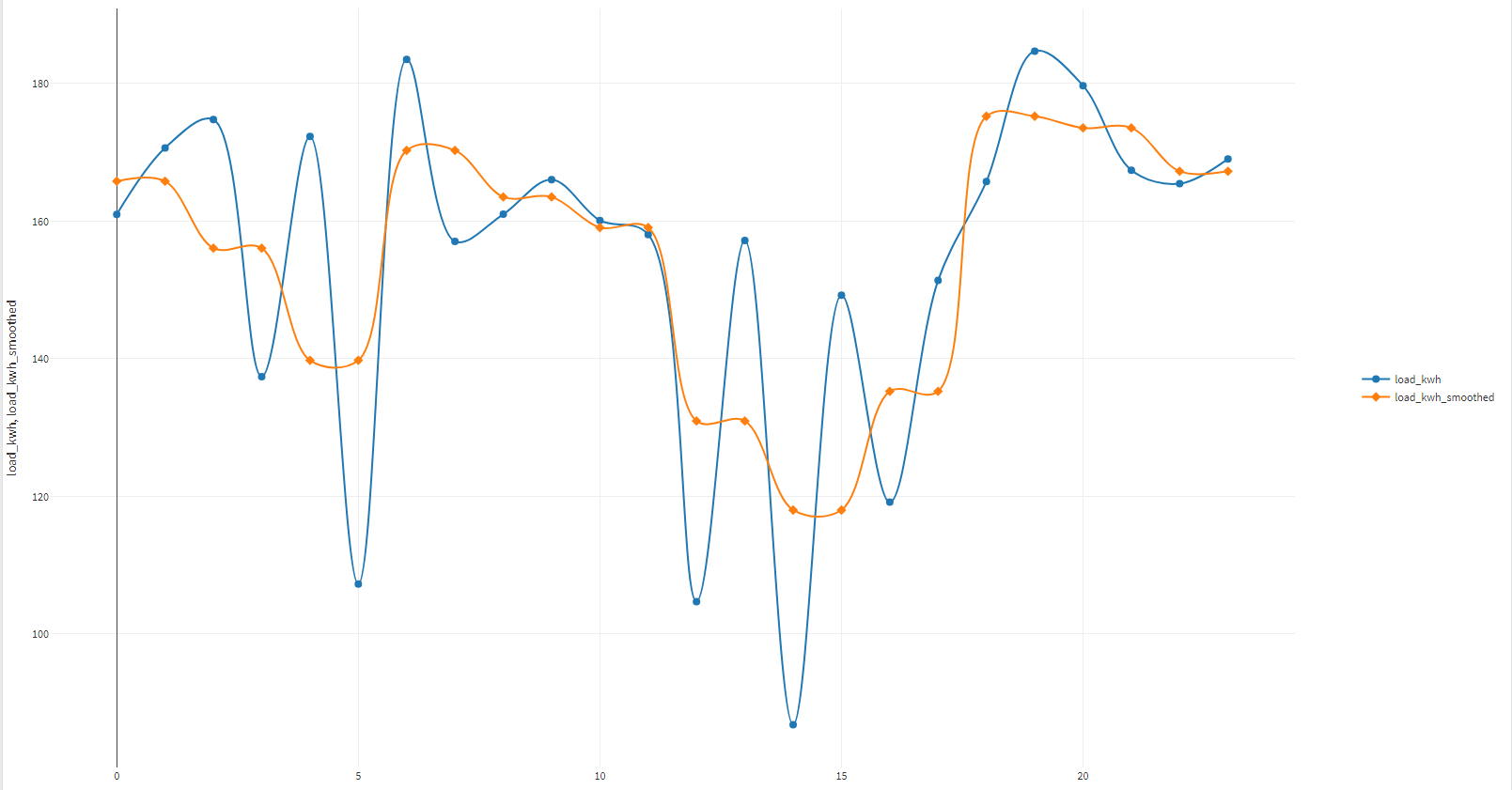
Smoothing result in Megaladata
Calculator creates new fields in a dataset using formulas based on existing data or JavaScript code. It improves data quality by deriving new information, reducing manual calculation errors, and enabling more comprehensive analysis.
Megaladata's data cleaning and preprocessing tools: Utility across industries
In Customer Relationship Management (CRM), the Megaladata platform can help to eliminate duplicate records and impute missing customer information for targeted marketing. For financial analysis, Megaladata is able to detect outliers, smooth time series data, and prevents erroneous calculations. In healthcare, it is capable of cleaning patient data for accurate diagnoses and research. While in the scientific field, it can provide data reliability by removing duplicates and handling missing values.
These Megaladata capabilities empower businesses and researchers to extract maximum value from their data.
In conclusion
Data quality issues are inevitable and have to be resolved in the very beginning of any data analysis project. Advanced analytics platforms like Megaladata provide tools for fast and convenient data quality assessment. Once the issues are discovered, you can significantly improve data quality by cleaning up errors, filling in gaps, and employing other built-in data preparation components. This way, you ensure that your data is fit for any complex model or impactful project.
Megaladata is the world's fastest platform for data analysis! Get ready to experience performance that's over ten times higher—download the free Megaladata Community Edition.
Read more:
See also

Megaladata at e-Logi Fest 2026

How Low-Code is evolving ETL
In 2026, you cannot scroll LinkedIn for five minutes without finding a post declaring "ETL is dead, ELT and AI have replaced it." It sounds compelling. It is also wrong.

Megaladata at Plug and Play Armenia Batch 3 Expo
On July 9, 2026, Megaladata took part in the Plug and Play Armenia Batch 3 Expo, the graduation event closing out the three-month International Pre-Acceleration Program in Armenia.
About Megaladata
Megaladata is a low code platform for advanced analytics
A solution for a wide range of business problems that require processing large volumes of data, implementing complex logic, and applying machine learning methods.
GET STARTED!
It's free