On July 17-19, 2026, Megaladata took part in e-Logi Fest 2026, Armenia's leading international event dedicated to logistics, e-commerce, and supply chain innovation.
Cleaning Data Using the Duplicates and Contradictions Component


Data quality is an important aspect that directly impacts the results of analytical processing. There are many factors that can lead to data contamination. A typical problem is the occurrence of duplicate records. This article discusses the use of the Duplicates and Contradictions component to quickly find records with fully or partially matching fields.
Duplicate records are a common challenge when working with large datasets, especially when consolidating information from different sources. These duplicates often result from simple errors or incorrect client information.
A record can be a complete duplicate (identical to other record) or a contradiction (a partial duplicate containing some information contradicting another record). Complete duplicates are redundant because the data already exists. During data cleanup, all such copies are deleted, leaving only a single record.
Handling data contradictions is more complex than handling complete duplicates, as they can represent either valid information or critical errors.
The correct approach depends entirely on the context. For example, a loan database may contain two borrowers with identical names but different ID numbers and debt amounts. These are likely two distinct individuals, and the records cannot be deleted or merged. Conversely, a single product listed in a store's database with two different prices is clearly an error that must be resolved immediately to avoid sales issues.
Allowing duplicates and contradictions to accumulate degrades the quality of your data. This can distort information used for management decisions, leading to increased costs and reputational damage. It is therefore essential to identify and resolve these data issues promptly.
Below is a Megaladata workflow that detects and removes duplicate records of bank credit clients.
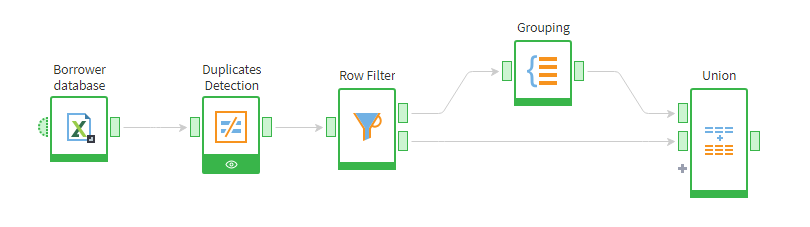
Duplicate detection workflow
The table below shows the client's full name, unique identifier, and loan amount in euros.
| Identifier | Surname | First Name | Middle Name | Credit, EUR |
|---|---|---|---|---|
| 105441 | Thompson | James | Robert | 2457.84 |
| 105442 | Mitchel | Elizabeth | Anne | 354.35 |
| 105442 | Mitchel | Elizabeth | Anne | 354.35 |
| 105443 | Harris | Michael | Christopher | 751.2 |
| 105444 | Bennet | Olivia | Grace | 34.53 |
| 105445 | Campbell | Sarah | Jane | 67.43 |
| 105445 | Campbell | Sarah | Jane | 67.43 |
| 105446 | Campbell | Sarah | Jane | 3543.54 |
| 105447 | Clarke | Benjamin | David | 414.25 |
| 105448 | Clarke | Benjamin | David | 542.13 |
| 105449 | Walker | Emily | Rose | 755.31 |
| 105450 | Parker | William | John | 578.41 |
| 105451 | Foster | Daniel | Thomas | 534.34 |
| 105451 | Foster | Daniel | Thomas | 534.34 |
| 105452 | Hughes | Sophia | Marie | 575.47 |
| 105453 | Reed | Matthew | Alexander | 3543.94 |
| 105454 | Morgan | Charlotte | Lily | 244.23 |
| 105455 | Butler | Samuel | George | 687.45 |
| 105456 | Richardson | Amelia | Kate | 585.74 |
We will analyze information about borrowers in order to clear the data of duplicate entries.
Finding duplicates and inconsistencies
Megaladata has a specialized Duplicates and Contradictions component for finding full and partial copies of records. To use it, simply drag it into the workflow area and connect your source data to the input port.
Configuring the node is straightforward; you just assign one of three settings to each column:
Unspecified. This setting means that the column will be ignored during the comparison. It is set as default for all columns.
Input. Records with identical values in input columns will be searched for, and the values of their output fields will be compared.
Output. Within each group of records with identical input columns, the system will compare the values in these output columns. If the values match, the records are flagged as duplicates. If they differ, they are flagged as contradictions.
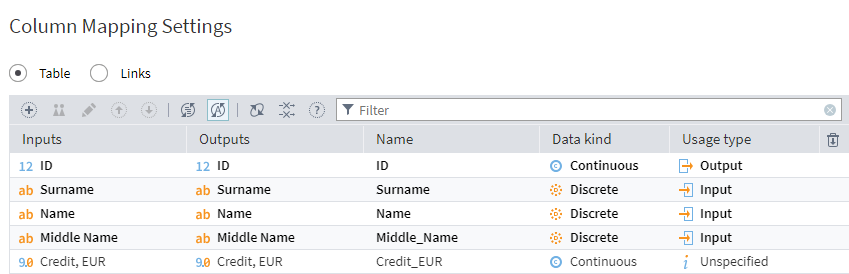
Column mapping of the Duplicates and Contradictions node
On activation, the node will check each source data record for duplicates or contradictions. The node's output will list all inconsistencies and duplicates in a table.
Visualizer
To review these results, there is a dedicated visualizer, available within the Duplicates and Contradictions node only. Go to the node's visualizers (the 'eye' icon on the node) and select Duplicates and Contradictions in the Visualizers pane on the right. Drag it to the Add visualizer area in the Component section of the main workspace. (You can also just click Add visualizer after selecting).
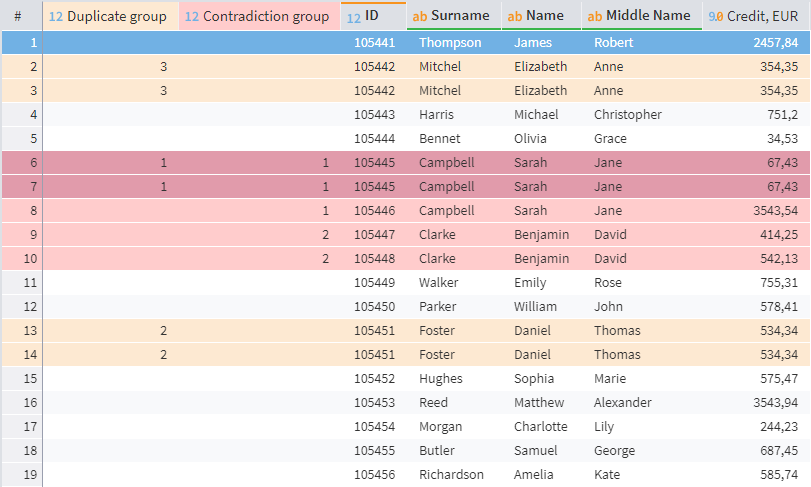
Duplicates and Contradictions visualizer
By default, the visualizer adds two columns to the source table: Duplicate group and Contradiction group, where each series is assigned a sequential number, starting with 1. If no matches are found, the fields are left blank. You can also configure the display of the Duplicate and Contradiction columns with true/false values.
In the resulting table, each record belongs to one of four types:
- Duplicates. Input and output fields are exactly the same. These records are marked in yellow.
- Contradictions. Records in which the input fields match, while the output fields differ. These rows are highlighted in pale pink.
- Duplicates and contradictions. Records that belong to two categories simultaneously. The ordinal numbers of the groups may not match. These records are highlighted in brighter pink.
- Unique records. Records for which there are no matches between input fields. Not highlighted.
In the example shown above, there are three groups of duplicates, each with two records. These create data redundancy, occupy disk space, and do not add any value to the dataset. During the cleanup process, one record from each group of duplicates should be retained and the rest deleted.
The table also displays two groups of contradictions. The first group has three records for two different people with coinciding names: two of these (ID 105445) are identical and will be processed as duplicates, while the third (ID 105446) was flagged as a 'contradiction' due to a different loan amount but is a valid record for a different person. The second detected group of contradictions presents a similar situation with valid data, so inconsistency processing is not necessary.
Removing duplicates
To clean up the data, we first need to sort the records marked as duplicates. We'll use the Row Filter component:
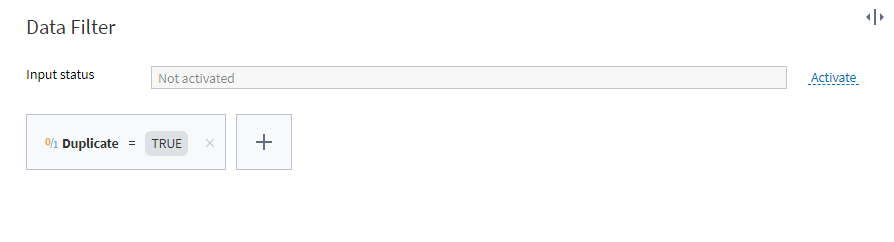
Setting up the row filter
With this filter, the first output port of the Row Filter node will display a table with all duplicates, and the second one will have all the remaining records.
Next, we'll combine the duplicate records using the Grouping component. In the settings, set Duplicate group as the grouping field, and move all other fields to Parameters. To ensure that the field values remain unchanged, we'll select the First aggregation type.
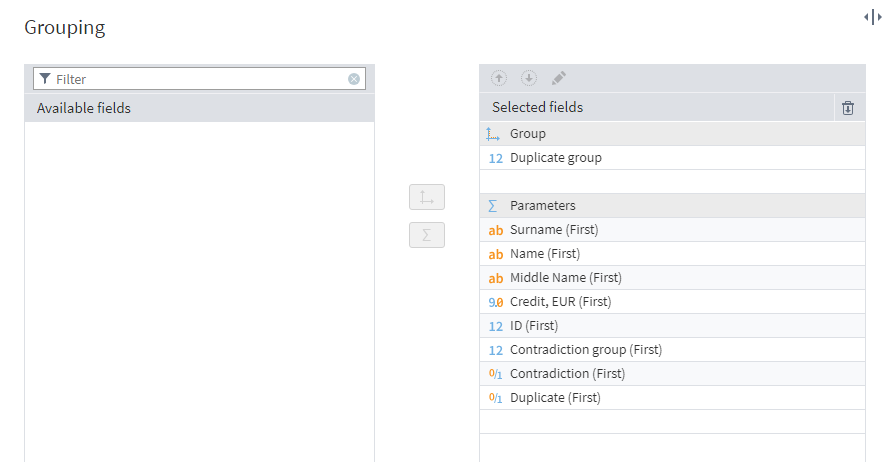
Setting up the grouping node
At the node's output port, a table with each duplicate group corresponding to only one record will be generated.
Next, we need to combine the resulting records and the data from the second output port of the Row Filter node into a single table. To do this, let's add a Union node to the workflow area. In the settings, we need map the fields of the main and joined tables.
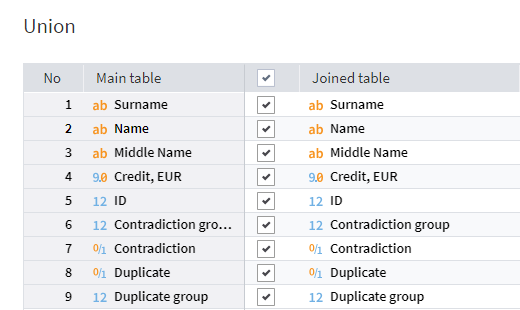
Setting up the Union node
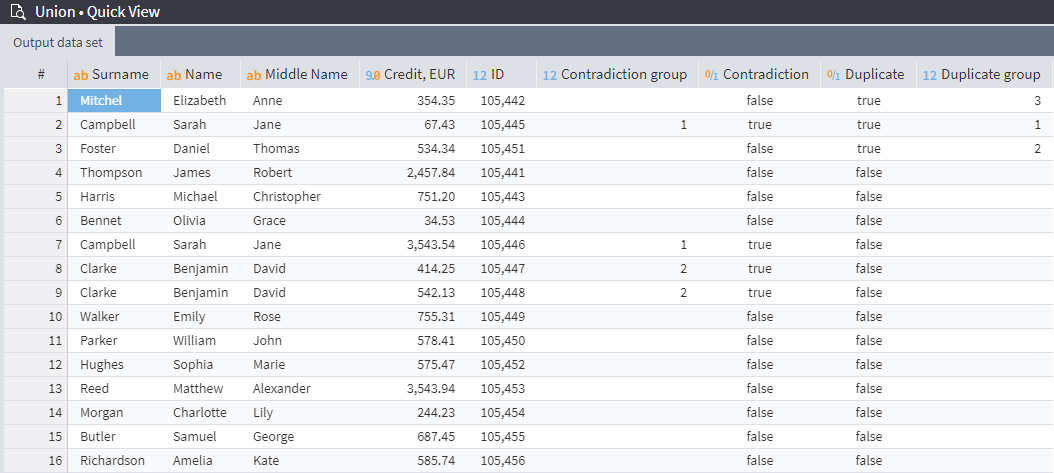
Cleaned duplicate-free table as a result
Automated data cleanup in Megaladata
When working with a data array, it is extremely hard to avoid the occurrence of any duplicates or inconsistencies.
Yet we know that such entries have negative consequences:
- Increased storage costs. Copies take up disk space, which sooner or later must be purchased physically or in the cloud.
- Redundant operations. Data manipulations will be performed on each copy of the data in the array. Their execution will consume additional resources.
- Skewed models. A model created from a training set containing duplicates or contradictions will produce distorted results.
- Complicating management decisions. Contaminated data does not reflect the true picture of the enterprise, which may lead to decision-making errors.
The consequences of poor data quality are especially damaging to the customer experience. Repetitive emails and calls are distracting and annoying, and duplicate data in a marketplace can lead to multiple payment requests for the same item, directly harming customer trust.
Megaladata's Duplicates and Contradictions component allows you to quickly find duplicate/contradicting records in a large dataset, and perform timely data cleaning using other handlers provided by the platform.
Read more on data cleaning:
See also

Megaladata at e-Logi Fest 2026

How Low-Code is evolving ETL
In 2026, you cannot scroll LinkedIn for five minutes without finding a post declaring "ETL is dead, ELT and AI have replaced it." It sounds compelling. It is also wrong.

Megaladata at Plug and Play Armenia Batch 3 Expo
On July 9, 2026, Megaladata took part in the Plug and Play Armenia Batch 3 Expo, the graduation event closing out the three-month International Pre-Acceleration Program in Armenia.
About Megaladata
Megaladata is a low code platform for advanced analytics
A solution for a wide range of business problems that require processing large volumes of data, implementing complex logic, and applying machine learning methods.
GET STARTED!
It's free