On July 17-19, 2026, Megaladata took part in e-Logi Fest 2026, Armenia's leading international event dedicated to logistics, e-commerce, and supply chain innovation.
Regular Expressions in Megaladata


Regular expressions are a powerful tool that allows you to perform complex operations on strings, such as data extraction, validation, replacement, or text splitting. In this article, we will consider the use of regular expressions in Megaladata. We will also explore some tasks for which other techniques are preferable.
Working with data often requires complex operations on strings. A typical task is to correct errors made by people when filling out forms or to combine information from several data sources.
Consider an example. A database contains two product codes: "A101" and "A102". These must be replaced with a single code "B100". Using a regular expression would allow you to complete this task in one step.
However, to work with regular expressions, you need to master their syntax. There are many web guides and applications that help create correct expressions, such as regex101.com. We recommend using these resources cautiously, as an erroneous regular expression may influence performance and even lead to data loss.
Regular expression syntax
Regular expressions are sequences of characters written following specific rules. Most often they are used for search and replace tasks which require complex conditions. Think of a regular expression as a one-line program.
Regular expressions are often integrated into programming languages and software tools. This results in variations in syntax. However, the basic rules are similar. Let's explore them below.
Character sets
Square brackets ([]) indicate an expression that matches a single character to the set contained within the brackets:
[abc]: matches the charactera,b, orc.[m,k t]: matchesm,k,t, comma (,), or space.[19]: matches the digits1or9.
A hyphen (-) within a character set indicates a range:
[0-5]: matches any digit from 0 to 5.[A-Z]: matches any uppercase letter from the Latin alphabet.[A-Za-z]: matches any uppercase or lowercase letter from the Latin alphabet.
To exclude characters from a set, use a caret ^ at the beginning:
[^xyz]: matches any character other than "x", "y", or "z".
Line anchors
The caret ^ and dollar $ characters are anchors that mark the beginning and end of a line, respectively. For instance:
^A: matches an "A" only at the start of a line.n$: matches an "n" only at the end of the line.^...$: matches the entire string pattern from start to finish.
Metacharacters
Metacharacters are special characters with a predefined meaning in regular expressions. They include the following characters:
. ^ $ * + ? { } [ ] ( ) \ and |
To treat a metacharacter as a literal character, you must "escape" it with a backslash \.
Quantifiers
A quantifier after an element specifies how many times the preceding element (i.e., a character, group, or class of characters) is allowed to repeat:
{n}: exactly n times {n,}: n or more times {n,m}: at least n times, but no more than m times.
For example, ^[0-9]{4}$ matches any string containing exactly four digits.
Commonly used quantifiers have shorthand symbols:
*: zero or more times. Equivalent to {0,}
+: one or more times. Equivalent to {1,}
?: zero or one time. Equivalent to {0,1}
For example, the expression Johnsons? would match both "Johnson" and "Johnsons".
By default, quantifiers are "greedy", meaning they match the longest possible string. For example, in the string <p>text</p><p>more text</p>, the greedy pattern <.+> would match the entire string from the first < to the final >.
Some quantifiers have two variants:
- The greedy variant: The quantifier intends to match the maximum possible number of occurrences of the element.
- The non-greedy, or lazy, variant: The lazy quantifier intents to match the minimum possible occurrences of the element.
To make a quantifier "lazy", add a ? after it. For example: The lazy pattern <.+?> would match any character that occurrs one or more times between <p> and </p>.
Groups and capturing
If grouping of atoms is necessary, a pattern can be enclosed in parentheses ( ). The pattern part in parentheses is called a "parenthesized group".
Example: Without parentheses, the pattern ma+ matches the character m followed by the character a occuring one or more times (e.g., maaa or maaaaaaa). Parentheses group characters together: (ma)+ matches ma, mama, etc.
When a part of a regular expression is enclosed in parentheses, the quantifier is applied to it as a whole. Parenthesized groups are numbered from left to right.
You can exclude a parenthesized group from being remembered by adding ?: to its beginning. This way, it allows you to apply quantifiers and other operators to a part of the pattern, but does not create a separate group to save the found text.
For example, the regex (?:[0-9]{3}-)[0-9]{2}-[0-9]{4} could match a US Social Security Number (e.g., "123-45-6789") but would not create a separate captured group for the first three digits and hyphen.
Special character classes
For convenience, regex includes special classes for common character types:
\d: any digit (equivalent to[0-9])\w: any "word" character (letters, numbers, and underscore) (equivalent to[A-Za-z0-9_])\s: any whitespace character (space, tab, newline)
For example: \d{3} matches any three-digit sequence, and \w+ matches any word.
Mastering regular expressions is a valuable skill for performing sophisticated text processing in a single line, often avoiding the need for more complex code. This was a brief overview; you can find more detailed documentation online, for example, here.
Regular expressions in Megaladata
The Megaladata platform uses the Perl Compatible Regular Expressions PCRE2 library. It allows you to use Perl-style regular expressions with some differences. The PCRE2 syntax is more powerful and flexible than standard POSIX regular expressions.
In Megaladata, when working in the Calculator in JavaScript mode, the regular expressions of this language are available, with a syntax different from PCRE2. You can read more about regular expressions with JavaScript here.
Common tasks and functions
Using regular expressions on the Megaladata platform, you can solve tasks like:
- Searching and flexible replacement of text
- Data preparation, cleaning, and processing
- Minimizing the need to write complex custom code
To accomplish this, you can use the built-in functions of the Calculator component:
- RegExEmail: Extracts an email address from a string.
- RegExDomain: Extracts a website address (domain name) from a string.
- RegExMatch: Checks if a string matches a regular expression, returning
trueorfalse. - RegExMatchedExp: Returns the portion of a string that matches a regular expression.
- RegExMatchCount: Returns the number of times a pattern is found in a string.
- RegExMatchedNamedSubExp: Returns a substring group matching the regular expression.
- RegExMatchedSubExp: Extracts a captured subgroup by its number.
- RegExReplace: Replaces the first occurrence of a pattern in a string.
- RegExReplaceAll: Replaces all occurrences of a pattern in a string.
Beyond the Calculator, regular expressions are also used in the Replace component. This component is designed to replace data in a source set using a replacement table. The search and replace operations can be configured to work by either exact match or by using a regular expression.
To improve performance, a cache of compiled regular expressions is used at the application level, rather than at the session level. The cache stores regular expression patterns that are used only when functions are called. This eliminates the need to re-parse the expression each time it is used, reducing processing time.
By default, up to 16 compiled regular expressions are cached. When the number of compiled regular expressions is exceeded, the oldest one in use is removed from the cache and a new one is added.
Since regular expressions need to be compiled, their use can reduce the speed of program execution and increase memory consumption. However, the Megaladata platform has alternative options for working with strings that can be more efficient in some cases.
When to avoid writing regular expressions
Regular expressions are powerful, but they aren't always the best choice. For simple operations like finding specific words, simple text replacement, or extracting substrings from a fixed position, using Megaladata's built-in string functions is often a cleaner and more efficient solution.
Replace an entire line or word
There is no need for regular expressions to replace a string. Megaladata has a Replace component, which can replace a string by an exact value, e.g., a phone number or passport data.
Alternatively, you can use the Replace function in the Calculator: Replace(Name,"A101","B101", true, true).
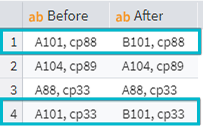
Word replacement
Check a date
While you can use a complex regex to validate a date, it's cumbersome and error-prone. The Calculator provides the StrToDate function, which converts a string to a date/time format much more easily.
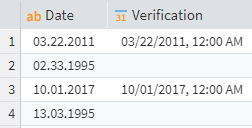
Check a date with StrToDate function
Selecting a substring
To extract a specific number of characters from the beginning or end of a string, use the Left or Right functions in the Calculator, as shown in the image:
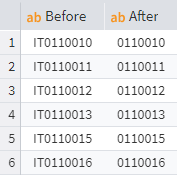
Using the Right function in the Calculator
To extract a substring of a certain lengths, which starts from a specific position, use the SubStr function.
Ready-made regular expressions
You don't need to write complex regular expressions to validate emails or domains yourself. The Calculator has built-in RegExEmail and RegExDomain functions for these tasks.
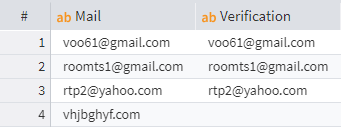
Validating emails
However, for non-trivial tasks, regular expressions are often the optimal choice. Let's look at some examples using the Calculator component in Megaladata.
Regular expressions for non-trivial tasks
Case 1: Removing unnecessary characters
Consider the task of removing all periods and semicolons from a table field.
Example 1: Use the RegExReplaceAll function with the necessary arguments:
RegExReplaceAll("[.;]", Name, "")
where
"[.;]"are the characters we need to deleteNameis the table's field that requires the transformation""is a string to replace the deleted characters with. In our case, it's an empty string, meaning the matched characters will be deleted.
The result of the transformation is a new field (on the right):
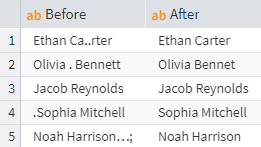
Removing unnecessary characters
Example 2: For the same task, you could use a different regular expression:
[^(a-z)|^(A-Z)|(\s)]
This regex would remove all characters but lowercase and uppercase Latin letters and spaces.
Case 2: Searching for specified strings
Below is a snippet of the source data from a database:
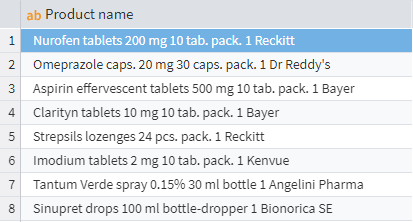
Source data
Imagine you need to find which drugs come in 20 mg or 200 mg packages. You can use the RegExMatch function:
RegExMatch("((20)|(200)) mg", Name)

Search for specified strings
Case 3: Phone number validation
To validate a US-style phone number, you can use the following function with arguments:
RegExMatchedExp("^(\+?1[\s-]?)?\(?[2-9][0-9]{2}\)?[\s-]?[2-9][0-9]{2}[\s-]?[0-9]{4}$", Phone)
It returns only those numbers that have passed validation, allowing for various formats like +1 (917) 422-7810 while correctly ignoring incomplete or improperly formatted entries like 323-864-950 and 206-555.

Validating phone numbers with a built-in regex
Case 4: Separating text and numbers
Example 1: Extracting the surname
Imagine a column contains both a surname and passport details, and you need to separate them. To extract the surname, you can use a regular expression that finds a word starting with a capital letter followed by lowercase letters:
RegExMatchedExp("[A-Z][a-z]+", "Initial data")
This pattern matches a sequence of characters that starts with one uppercase letter ([A-Z]) and is followed by one or more lowercase letters ([a-z]+). In the example "Harrison 745628776", this correctly isolates "Harrison".
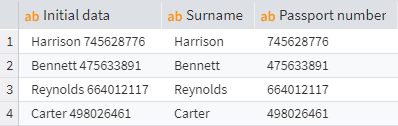
Extracting the surname
Example 2: Extracting the passport number
To extract the number, you can use an expression that looks for a sequence of digits:
RegExMatchedExp("[0-9]+", "Initial data")
This pattern matches one or more consecutive digits ([0-9]+). In the first row (the "Harrison" string of the "Initial data" field), this will find and return "745628776".
Case 5: Extracting a contract number
If a string contains a contract number mixed with other characters and a date, you can split them. Use RegExMatchedExp with [0-9]+ to get the number, and then use the Right and StrToDate functions to extract and convert the date.
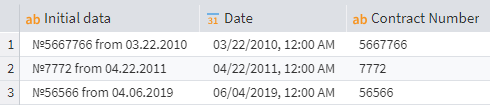
Selecting numbers of different lengths
Case 6: Searching for string occurrences
Consider a column that contains information about product ingredients. We need to find out which products contain "gelatin" or "sucrose". Let's use the RegExMatch function, which checks the string for a match:
RegExMatch("(gelatin)|(sucrose)", Ingredients)
Here is the result we get:
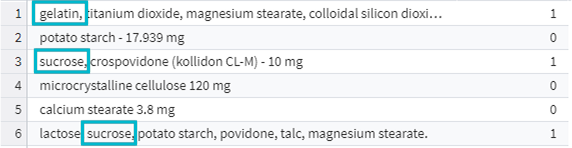
Finding occurrences of specific strings
When to use regular expressions
Using complex regular expressions on large datasets can slow down performance, as they require significant processing power. The impact on speed is often unnoticeable with a small amount of data but can become significant as the volume increases.
Here is the bottom line: Use regular expressions when simpler, built-in string functions are not sufficient for the task. Regex is not a rigid standard, but rather, a flexible tool for solving specific text-processing problems. The same task can often be accomplished in several ways. However, while different expressions might produce the same result, some will be more efficient or easier to read than others.
Using regex in Megaladata: pros and cons
Using regular expressions in Megaladata involves trade-offs:
Pros:
- Solving complex problems: Regex can handle challenging text-processing tasks where standard functions fail.
- No custom code required: Regex allow for advanced text manipulation without writing scripts in a full programming language.
- Built-in patterns: The platform provides ready-to-use expressions for common tasks, like validating email addresses and domains.
Cons:
- Difficult syntax: Regex syntax can be hard to learn for inexperienced users.
- Slower performance: Regex processing is generally slower, compared to simple, built-in string functions.
- Possible errors: The complexity of regex means expressions can have subtle bugs that require careful testing to find.
- Limited functionality: Regex in Megaladata are less powerful than the regex engines found in dedicated programming languages like Python or Perl.
Conclusion
Regular expressions are a powerful tool, but they require careful use. For detailed guides, examples, and online testing tools, you can consult the documentation. Online resources can make developing and debugging regular expressions much easier.
While regex syntax is often more concise than a full programming language, they are best reserved for complex tasks that truly require them.
See also

Megaladata at e-Logi Fest 2026

How Low-Code is evolving ETL
In 2026, you cannot scroll LinkedIn for five minutes without finding a post declaring "ETL is dead, ELT and AI have replaced it." It sounds compelling. It is also wrong.

Megaladata at Plug and Play Armenia Batch 3 Expo
On July 9, 2026, Megaladata took part in the Plug and Play Armenia Batch 3 Expo, the graduation event closing out the three-month International Pre-Acceleration Program in Armenia.
About Megaladata
Megaladata is a low code platform for advanced analytics
A solution for a wide range of business problems that require processing large volumes of data, implementing complex logic, and applying machine learning methods.
GET STARTED!
It's free