On July 17-19, 2026, Megaladata took part in e-Logi Fest 2026, Armenia's leading international event dedicated to logistics, e-commerce, and supply chain innovation.
What’s New in Megaladata 7.2


We have added a built-in Job Scheduler and a new OpenID authentication method employing Access Token. The list of data trees-related components was enhanced with the Calculator (Tree) component. Several files of the same structure can now be imported in the same import node. Adding filter conditions when configuring database import is available. The Cube visualizer now supports setting up several charts. We have updated the list of functions for the Calculator and Grouping components. You will also find some new features in user interface and administration.
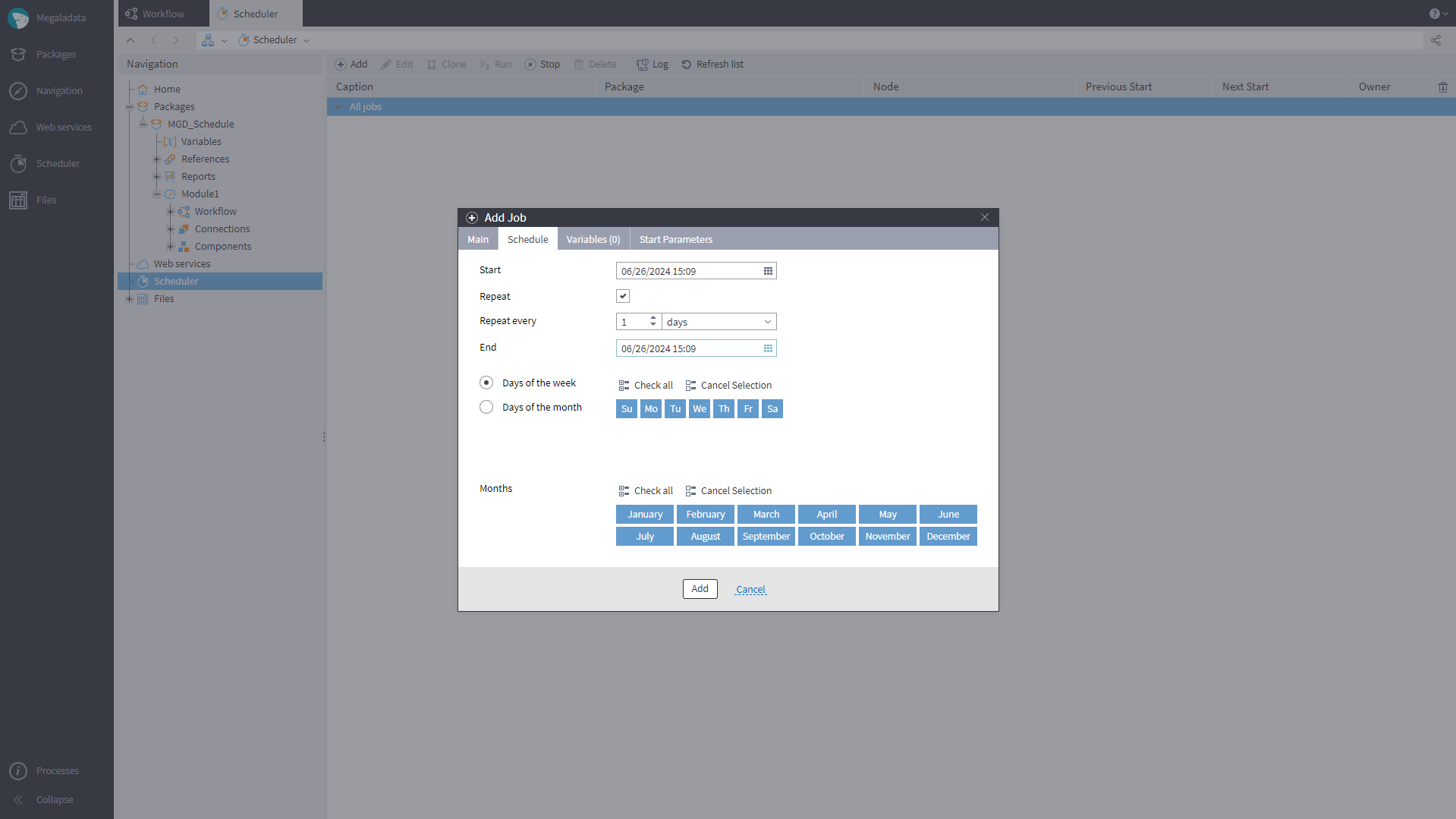
Built-in Job Scheduler
You can now set up scheduled batch launching of workflows in the Megaladata interface. The job scheduler is available in the server editions; you can open it via the Main Menu (a command on the side panel) or via the Navigation menu. On the Scheduler page, a user with workflow design rights can create a job, configure its parameters, and schedule execution. Scheduler management commands and an event log are also available. The event log tracks processing statuses for active and completed sessions and is saved in an SQLite database on disk. To create jobs, users will also need batch execution rights.
The Scheduler page allows users to run jobs manually (not only on schedule).
New User Authentication Method (Enterprise Edition)
We have added OpenID user authentication with Access Token. This allows user authorization based on roles and privileges stored in the token (meaning information about the user rights within Megaladata comes from external systems). The new authentication method is available in the Enterprise edition.
In the Administration section, you will find a set of OpenID configuration parameters. These parameters are required for OpenID user authentication to function.
After you set up the OpenID parameters, a new button will appear on the Login page. The button text will either be "Login with OpenID" or the provider name you specified.
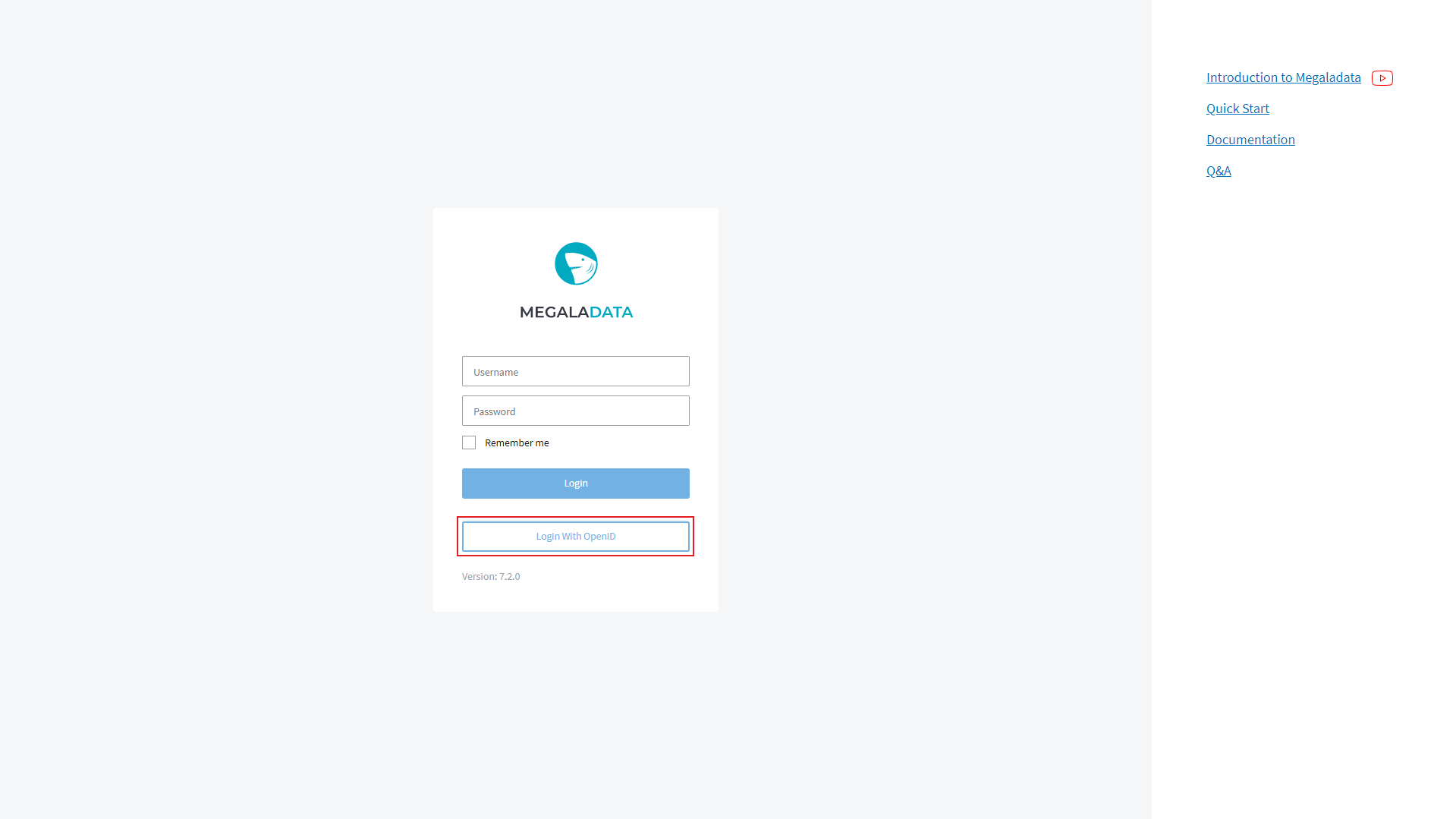
Clicking the button redirects you to the external authentication system's login page (the single sign-on scheme).
The OpenID authentication mode can be set up in the server.json configuration file using the openid parameter:
If the parameter is set to auto, the Login page requests the OpenID parameters’ values set in the Administration section. The button “Login with OpenID” gets added based on those values.
If the value of that parameter is set to force, the system will attempt to redirect to the authentication and access management page for entering user login and password, without opening the Login page.
If the parameter’s value is none or false, OpenID is not used and there is no request for OpenID configuration.
Updated List of Session Variables
The variables obtained from the OpenID token were added to the Session Variables. An OpenID access token can contain additional user data, for example, their residential area and so on. This information can be used in workflows, this is why some token claims (the data from the token in the form of claim name - claim value pairs) were added as variables to the Workflow Variables node. The list of variables can be configured via OpenID Parameters in the Administration section.
A New Component to Work with Data Trees
A new component, Calculator (Tree), was added to the set of standard components. A node based on this component has input and output ports of the Tree type. There is also an optional port for input variables. The expressions in the Calculator (Tree) are displayed as in a flat list; their hierarchy is maintained through complex names of the Expressions. Elements of the path are separated by dots. The Expression value is defined by a JavaScript function, that is, Calculator (Tree) only works in JavaScript mode.
The node supports all functions of Calculator (Variables) along with some specific ones:
Location (): Returns the path from the tree root to the expression.Parent (): Returns the parent node for the current node of the expression.ItemIndex (): Returns the expression’s index inside the parent array node of the current expression.ItemCount (): Returns the number of expressions inside the parent array node of the current expression.DisplayName ([“NodePath”]): Returns the caption (displayed name) in the path of a node, variable, or expression.
We have also made some changes to other components that work with data trees, namely, to the configuration wizards of the Table to Tree and Tree to Table nodes:
- A new icon is set for container nodes.
- For array nodes, we use the same icon as in Calculator (Tree) and in the Input Data Tree and Output Data Tree ports.
Changes to Database Processing Components
When configuring a database connection, you now have the option to “Ask for password”. With this enabled, the system will request the database user's login credentials (username and password) during the first activation of Database Import/Export nodes in interactive mode or when clicking "Activate" in their configuration wizards. The login/password will not be requested again until the Connections node is deactivated. If the option “Ask for password” is enabled, entering login/password will also be required upon each connection test.
When the option “Ask for password” is on, the password set during database connection configuration will not be saved. In case of batch processing, when the node is being executed via the Job Scheduler or Megaladata Integrator, the system will make a connection attempt without a password. A record about no password provided will appear in the log.
In the case when a password cannot be set for a connection, the option “Ask for password” will not be displayed.
When configuring Import from Database, you can now set filtering conditions: There is a new page “Data Filter” in the import configuration wizard.
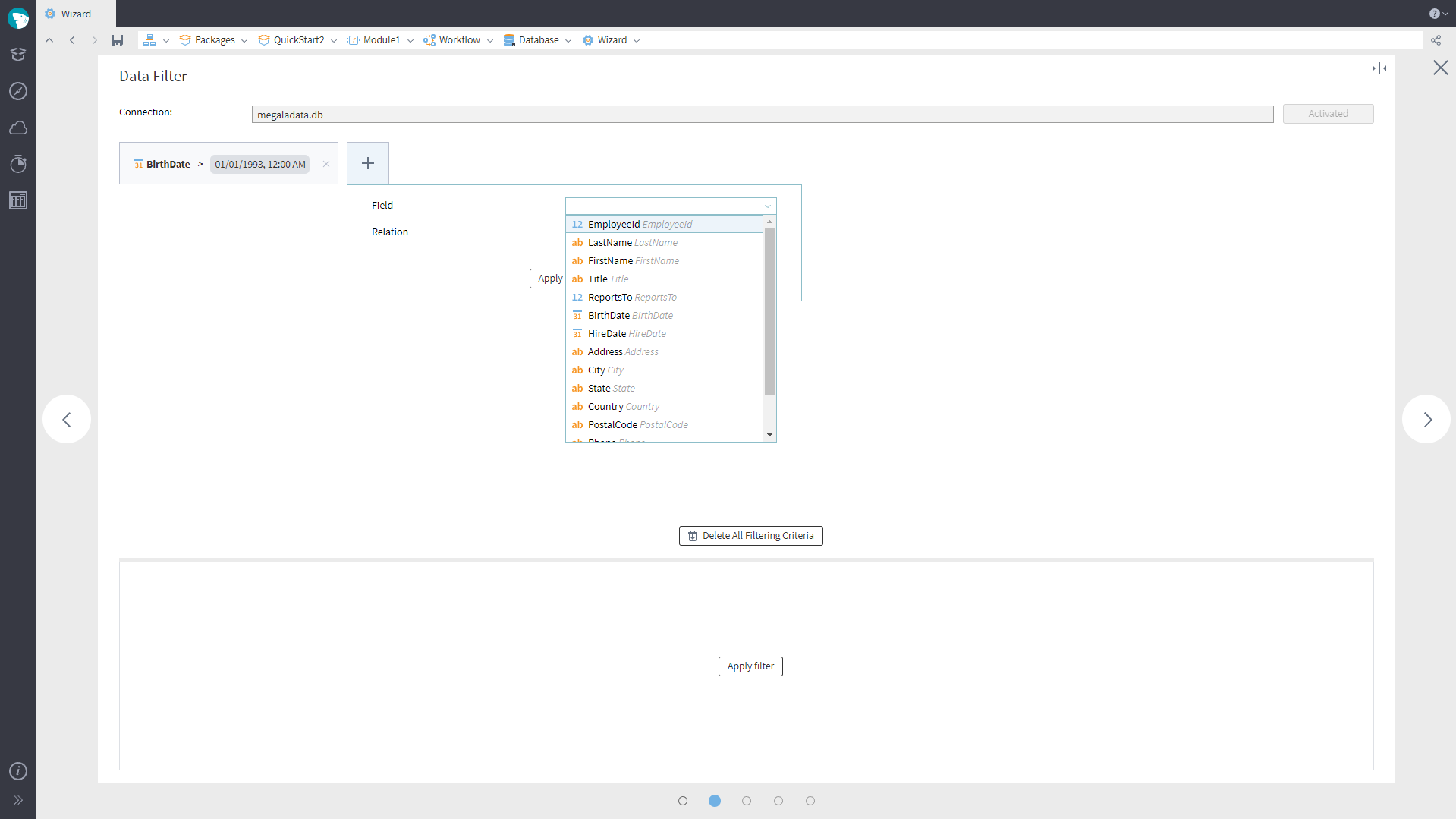
The filtering page appears second in the Database import configuration wizard. It will open if the Choose Table mode is on. However, no filtering conditions specified will not be considered an error. If filtering is not necessary, you can move on to the next wizard page. You can add and edit filter relations the same way as in the Row Filter component, although there are a few exceptions:
- No filtering by row number is available.
- There is no option to get a list of unique values for a field.
- The availability of the checkbox “Case-sensitive” for comparing rows depends on the DBMS and/or database collation and/or table collation. For example, in MS Access row comparison is always case-insensitive.
In the configuration wizard of Export to Database, there is now an opportunity to edit SQL scripts for creating tables. In the editor mode, syntax highlighting for the used SQL dialect will be activated. You can edit the request text and then run the request. The editor’s content is independent of the settings on the first page of the database export configuration wizard.
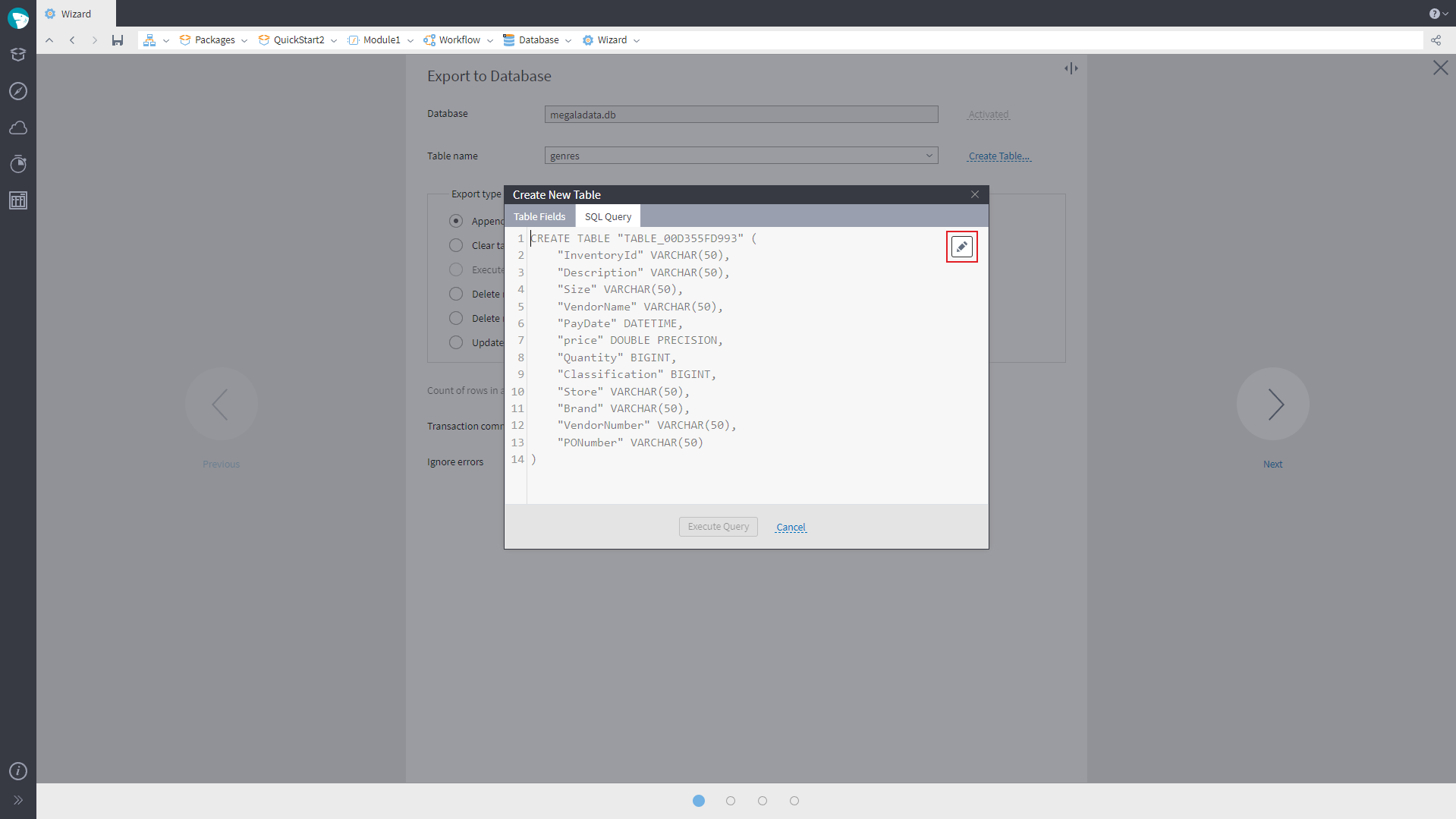
For SQLite, PostgreSQL, MSSQL, MySQL, Oracle and Firebird databases it is possible to execute several expressions in one SQL request (CREATE, INSERT, UPDATE, DELETE, DROP). For Oracle and Firebird, you will need to wrap them in a block; for Firebird, you will also need to add with autonomous transaction at the end of each expression.
We have added a TRUNCATE option to clear tables for exporting to databases. A new export type — TRUNCATE and append data — has appeared in the configuration wizard. It performs the same function as the Clear table and append data type, the only difference being that clearing the table will be performed through the TRUNCATE command instead of DELETE FROM. If a database does not support TRUNCATE operation (e.g. SQLite, Firebird, Access), this option will be unavailable. For all databases connected via ODBC this export type will always be available, since it is hard to detect if a particular database supports the operation. However, if the database does not support TRUNCATE, an execution attempt may end with an error.
When it is necessary to delete all table rows, TRUNCATE is faster than DELETE. Still, you need to take into account that the operation is not transactional. If a transaction or active table lock is performed simultaneously, it may result in an error. Also, it is impossible to undo the transaction after TRUNCATE.
Export to PostgreSQL now supports the JSONB type. In the workflows set up earlier, you will need to reconfigure export nodes (repeating all the wizard steps) to enable this option.
In the configuration wizard for Export to Database nodes employing ClickHouse, Oracle, and ODBC, it is possible to specify the number of rows in a batch. The default value is 1000 (with a minimum of 1 and a maximum of 1 000 000). Increasing the batch size can reduce export time significantly. For example, increasing the batch size from 1000 to 100 000 can reduce the time for exporting the same set:
- By ~ 54% in ClickHouse (for an ontime set, it is more than three times faster)
- By ~ 42% in Oracle
- By ~ 23% in ODBC
We have also added Microsoft OLE DB Driver 19 support for SQL Server.
Database field names in the Import from Database (“Table” mode) and Export to Database nodes now support “.”.
New Opportunities in File Sources Import
Many files of the same structure can now be imported in a single Import from Text File node. In the node configuration wizard, you can select several files and set the additional columns that will contain the information about the file (e.g., file name, relative path, etc.). The settings in the wizard will apply to all files. When determining the column types, rows from several files will be considered.
A file name may include wildcard search. In this case, all files corresponding to the pattern will be imported. The * character is used as the wildcard (e.g., /user/data/*.txt).
The Import from Excel File component has received similar functionality. On the first page of the configuration wizard, you can choose several files for import (or specify the glob pattern *.xlsx). However, only the first of the files found will be displayed on the wizard’s page (this limitation is based on Excel import specifics). All the other settings (named range, self-designated readable area, etc.) will also contain the data for the first file. The settings specified on this page will apply to all files you want to read. On the same page, you can also set additional columns for the file data.
The second page of the wizard displays data from all available files. The data will be read until the limit of Row count for analysis is reached. Columns are configured based on the data from the whole range of rows.
On the third page of the wizard, additional columns containing the information about the file will be added to the list of fields.
New Features of Processing Components
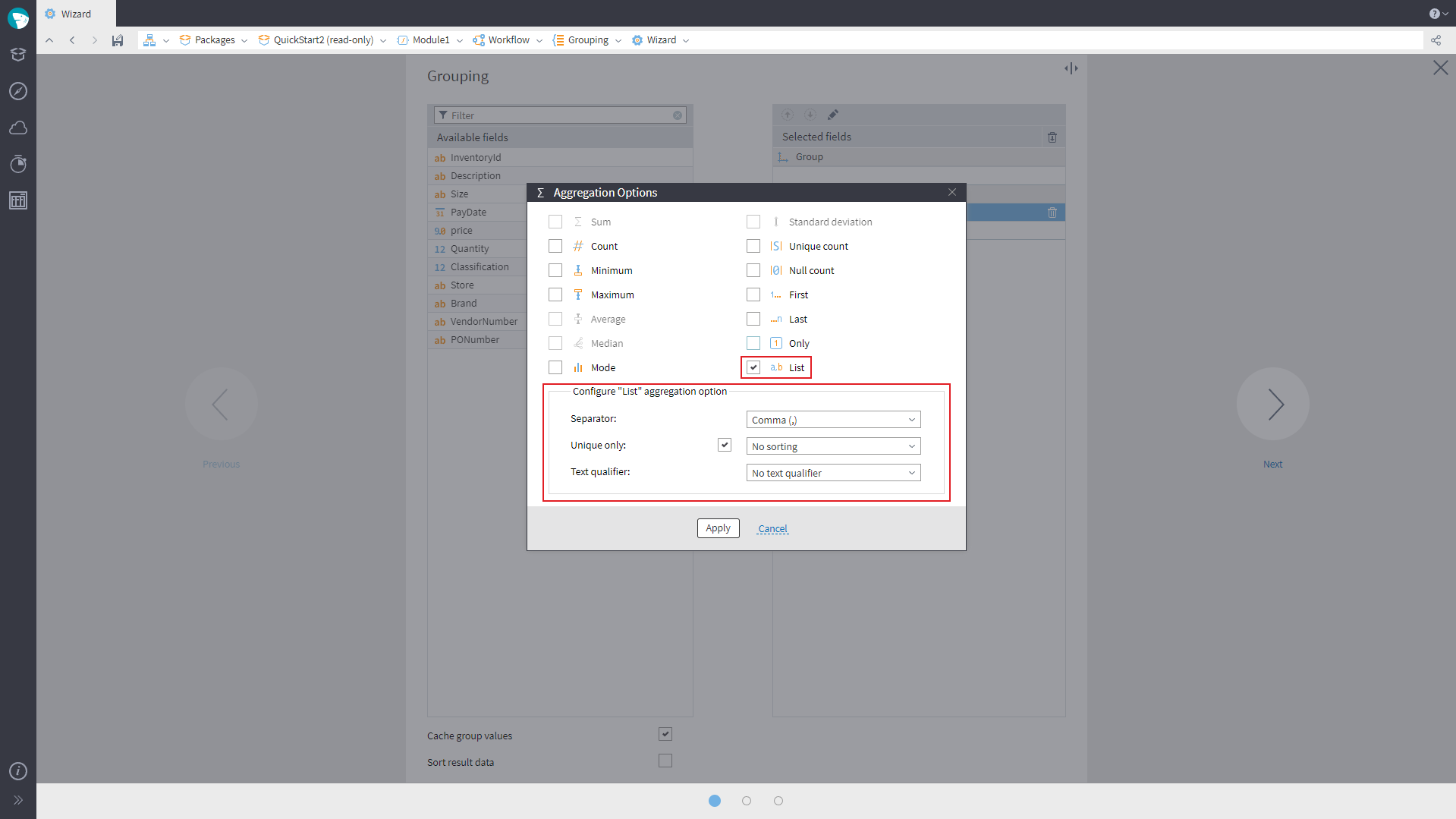
Components Grouping and Table to Variables have received a new aggregation option – List – which will allow you to transform values of a string field into a list with selected separator. It is possible to create a list with all field values or unique values only.
The configuration wizard of the Sort node has received a new option “Compare considering locale” (enabled by default). If you disable it, the comparison of rows will be binary, irrelevant to the package locale. This would increase operation speed in the cases when there is no point in locale consideration for sorting, for example, when a string field contains only Latin letters, numbers, and special characters. When both “Compare considering locale” and “Case-sensitive” options are disabled, the comparison will be done ignoring the case for Latin letters only.
A range of functions provided in Calculator was enhanced:
- With some math functions: RoundUp(Argument, NumbersAfterDecimalSeparator) for rounding up, RoundDown(Argument, NumbersAfterDecimalSeparator) for rounding down, and Div(Dividend, Divisor), which returns the quotient of integer division of the
Dividendby theDivisor. - With a Boolean function: NVLF(NumericalExpression[, Default_value = 0]), which returns the
NumericExpressionvalue if it is notNull, or else theDefault_value. - With functions operating with Date/Time:
- StartOfTheYear(Date), StartOfTheQuarter(Date), StartOfTheMonth(Date), StartOfInterval(Date, Interval_Count, Interval_Type[, Start_point]), returning a time interval start.
- HoursBetween(Date1, Date2), MinutesBetween(Date1, Date2), SecondsBetween(Date1, Date2), MillisecondsBetween(Date1, Date2), returning the number of complete time intervals between two dates.
- AddHour(Date, Number), AddMinute(Date, Number), AddSecond(Date, Number), AddMillisecond(Date, Number), adding several intervals to a date.
- EndOfTheYear(Date), EndOfTheQuarter(Date), EndOfTheMonth(Date), EndOfTheWeek(Date), returning the end of a time interval.
- UnixToDateTime(Date, [Initial_Date_In_UTC = True]), bringing a date in UnixTime format to the Date/Time format.
The functions that return a value between two dates (YearsBetween, MonthsBetween, DaysBetween, etc.) have also received an optional Boolean parameter Absolute_Value. If Absolute_Value = False and Date1 > Date2, the function will return a negative number of complete time spans between the dates.
In the functions that add some time spans to the date (AddDay, AddHour, etc.), the argument Count can now be negative. In this case, the function will return the date which is earlier by the specified number of time spans than Date.
Two new transformations were added to the Val function: Decimal_Separator and Thousands_Separator. Both parameters must be one character long. They may be any ASCII characters except numbers, + and – symbols and E. A NBSP Unicode character is also aссeptable as a Thousands_Separator. If both of these parameters are set, their values must not be the same, otherwise, the Val function will behave indefinitely. If Thousands_separator is not set, the value of the Decimal_Separator must differ from the thousands separator specified in the current package’s locale. If both parameters are not set, the row-to-number conversion will be performed based on the package’s locale.
We have optimized some functions operating with rows.
Adding and editing Expressions in Calculator will now be performed in a separate window and not in the list of expressions.
An expression setting “Replace field” was added to the Calculator's configuration wizard. If the option is enabled, and there is an input column with a name identical to Expression, the program will not add the new column but rather replace the existing one. A similar setting “Replace variable” was added to Calculator (Variables).
It is possible now to request an expression value if there is a column/variable with the same name. In the “expression” mode, this can be done using the Expr. prefix. In the JavaScript mode, use this.Expr. Functions Data and CumulativeSum now also support the Expr. prefix. Function DisplayName supports prefixes Var. and Expr.
For the lists of Fields/Variables, we have added a context menu with entries “Insert to expression” and “Add as expression”. You can now drag and drop fields and variables to the expression editing area and to the Code Editor.
You can use single quotes in the Calculator expressions — this will ease the use of “ character inside a string. String literals in single quotes are now highlighted in Calculator. Closing single quotes get added automatically.
We have added a comment switching hotkey Ctrl+/ to the expression code editors of the Calculator, Variables Calculator, and Calculated Measures of the Cube.
New Opportunities in the Cube
It is now possible to set up several charts in the Cube. We have added a button “Add Chart” at the upper right of the Cube’s toolbar. Up to three charts can be added. You can also attach charts to the right, at the bottom, and to the left, as well as delete them.
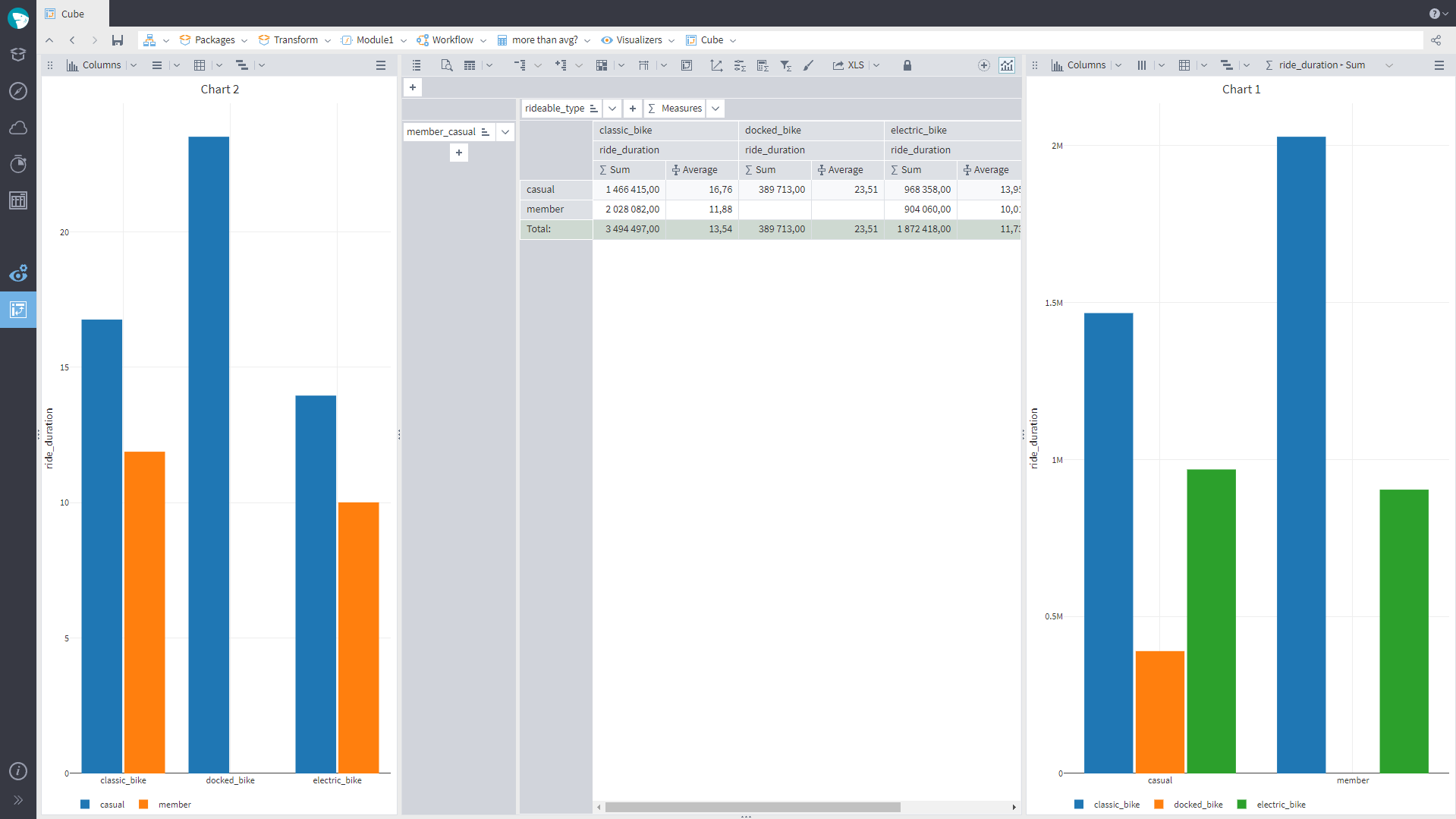
As the button “Add Chart” was added, the button named “Chart” is called “Charts” from now on. This button will not be available until you add the first chart.
We have added the opportunity to change the axis range of a Cube Chart with the mouse or the toolbar buttons.
In the Cube's Chart tooltips, the value is displayed with the precision set by the user in the Cube’s Cross-Table (The exact value with all decimal digits used to be displayed).
JavaScript and Python
We have added a new function, getLocale, to the global visibility area of JavaScript and Python code. For JavaScript, the function returns the locale’s name in the BCP 47. EcmaScript Language Tags format. For Python, it will be in ICU-defined format. The function getLocale will also be available in Calculator (in the JavaScript mode) and in Calculator (Tree).
An optional argument useNullableArrays was added to the function to_data_frame of the module builtin_pandas_utils. The default value for the argument is False. Setting useNullableArrays=True will allow you to perform a pandas.DataFrame conversion without losing the type. For an integer value column with nulls, pandas.arrays.IntegerArray is used. For a Boolean value column with nulls, pandas.arrays.BooleanArray is used. In all other cases, the operation will not be changed (nulls are supported using NaN values for real value columns, NaT values for Date/Time columns, and None for string columns.)
We have added support for filling-in output tables from pandas.DataFrame that contains typed columns with nullable data arrays: pandas.arrays.BooleanArray, pandas.arrays.DatetimeArray, pandas.arrays.FloatingArray, pandas.arrays.IntegerArray, pandas.arrays.StringArray., and pandas.arrays.StringArray.
In execution mode inside a Megaladata process, Python 3.12 is supported.
Administration
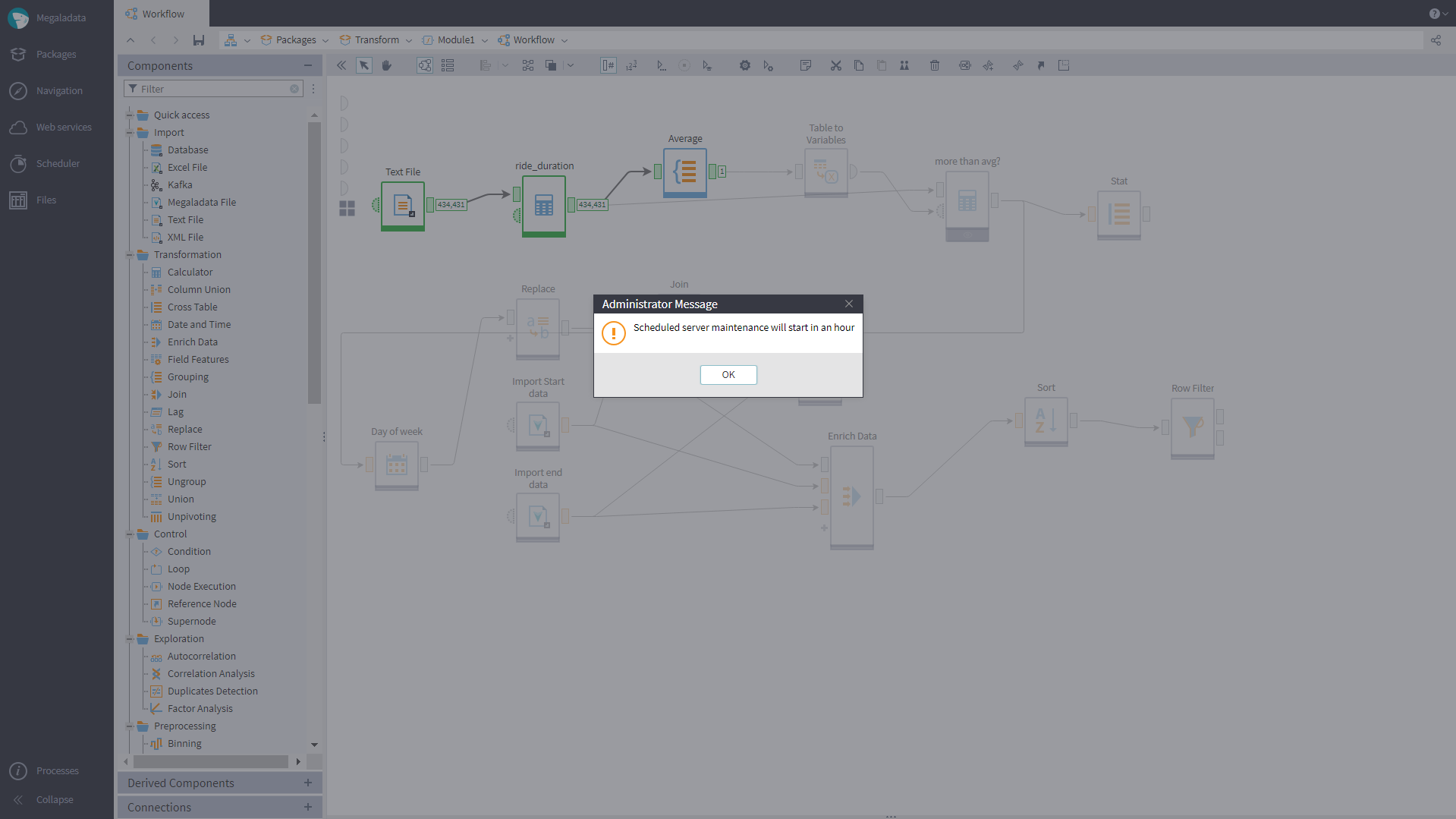
We have added the opportunity to send messages to users from the Session Manager. In the context menu of the Session Manager page, there are two new buttons: “Send Message” (to send a message to a selected user) and “Send Message to All” (to send a message to all active users). Upon clicking any of these buttons, a window for multi-line message text entry opens.
The users will receive the message as a window titled “Administrator Message” or as a pop-up message that never closes automatically.
Sending the message gets logged, with a list of session names to which the message was sent, and the message body.
Via the Session Manager, the administrator can send the server to maintenance mode. In this mode, logging-in to sessions is prohibited to anyone who does not have the Administration role. The administrator can now notify all active users about the upcoming maintenance via a message, and then switch to the server maintenance mode so that new users cannot log in.
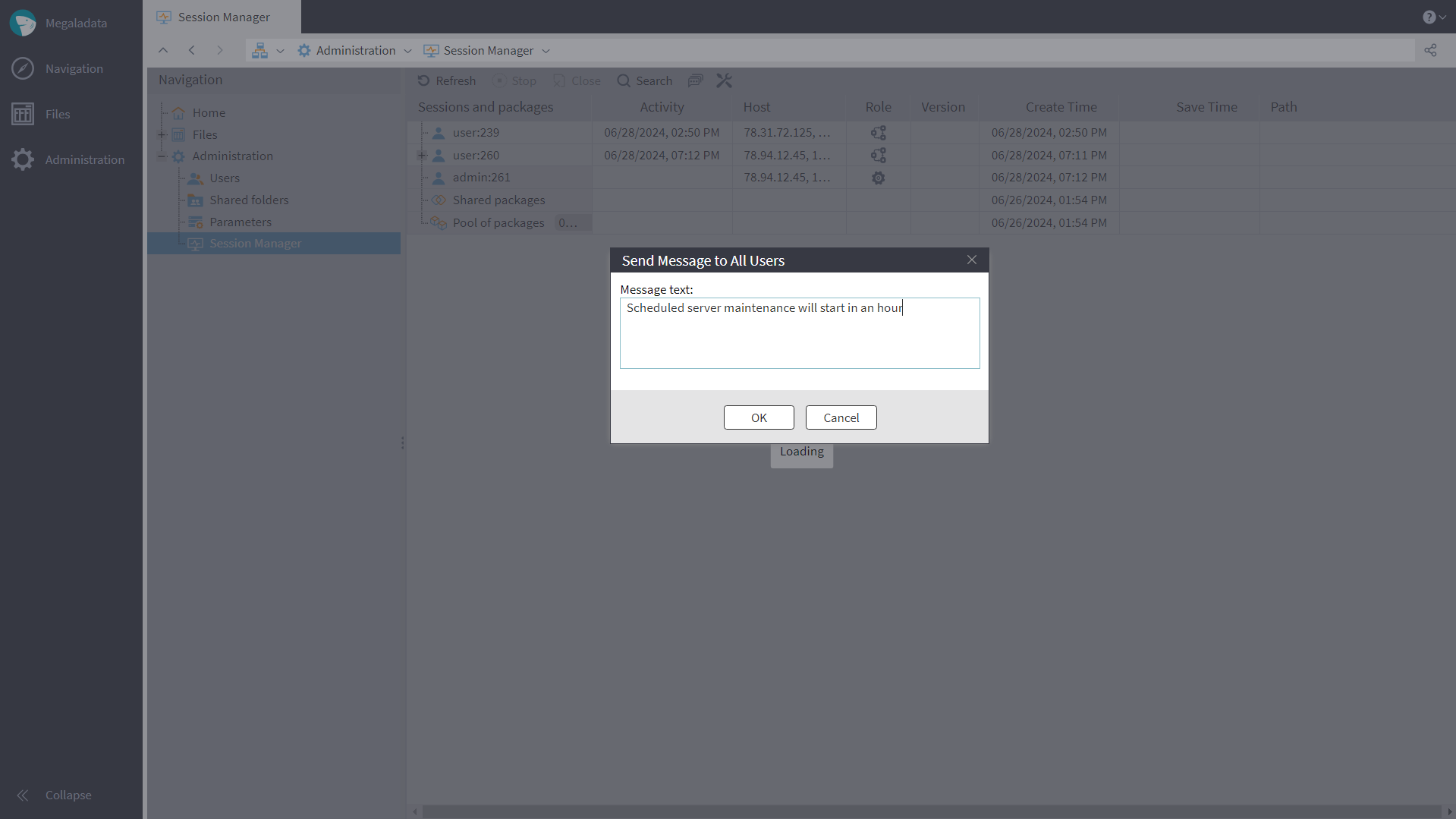
When the server is in maintenance mode, a user attempting to connect will get a maintenance message which the administrator composed upon entering the maintenance mode.
In maintenance mode:
- Processing any requests from Megaladata Integrator will stop, even if the session was open before entering server maintenance mode.
- Instead of starting tasks in the Job Scheduler, terminated sessions will be added to the Job Scheduler Log and receive a status “Not started”.
Beside this, there are no changes to the operation of the client and the server. The server still processes client´s requests. There are no additional restrictions to the users’ work.
Convenience of Use
The Main Menu has received new buttons for opening the “Web Services” and “Session Manager” pages. The buttons are hidden when the component is not available (e.g., in the desktop edition.)
There is now a “Quick Access” group on the Components panel. It can be configured in the context menu, to which some entries were added:
- Frequently used: A checkbox to specify if the frequently used components should be shown in the “Quick Access” group.
- Collapse groups: To collapse all the groups on the panel.
- Expand groups: To expand all the groups on the panel.
The “Quick Access” group provides convenient access to two categories of components:
- Favorite Components: These components are listed first and displayed in the order they were added. The user can add components to “Favorites”, move them within the group using drag-and-drop, and delete them from the group. The favorite components get a star icon on the left.
- Frequently Used Components: They are detected automatically based on the use statistics. The statistics of a component’s use updates when the user drags the component to the work area or uses the “Add node to the workflow” context menu. A component is considered frequently used if it was used more than five times or is one of the top ten (most frequently used) components but was not added to the favorite list. A component may be removed from frequently used via the context menu.
In the workflow building area, it is now possible to add captions to links. A caption can be added via the link’s context menu, by double-clicking the link, or pressing F2 (the link should be selected). The default value of a link caption is the same as the one of the output port, but it can be edited. A link caption cannot be longer than two lines.
We have also added captions to display the activated output ports' data amounts. For the ports with datasets, the number of rows in the set is shown, and for the ports with variables, the count of variables is displayed. By default, captions at the output ports are disabled. Displaying captions can be enabled using the button “Show count at output ports” in the toolbar.
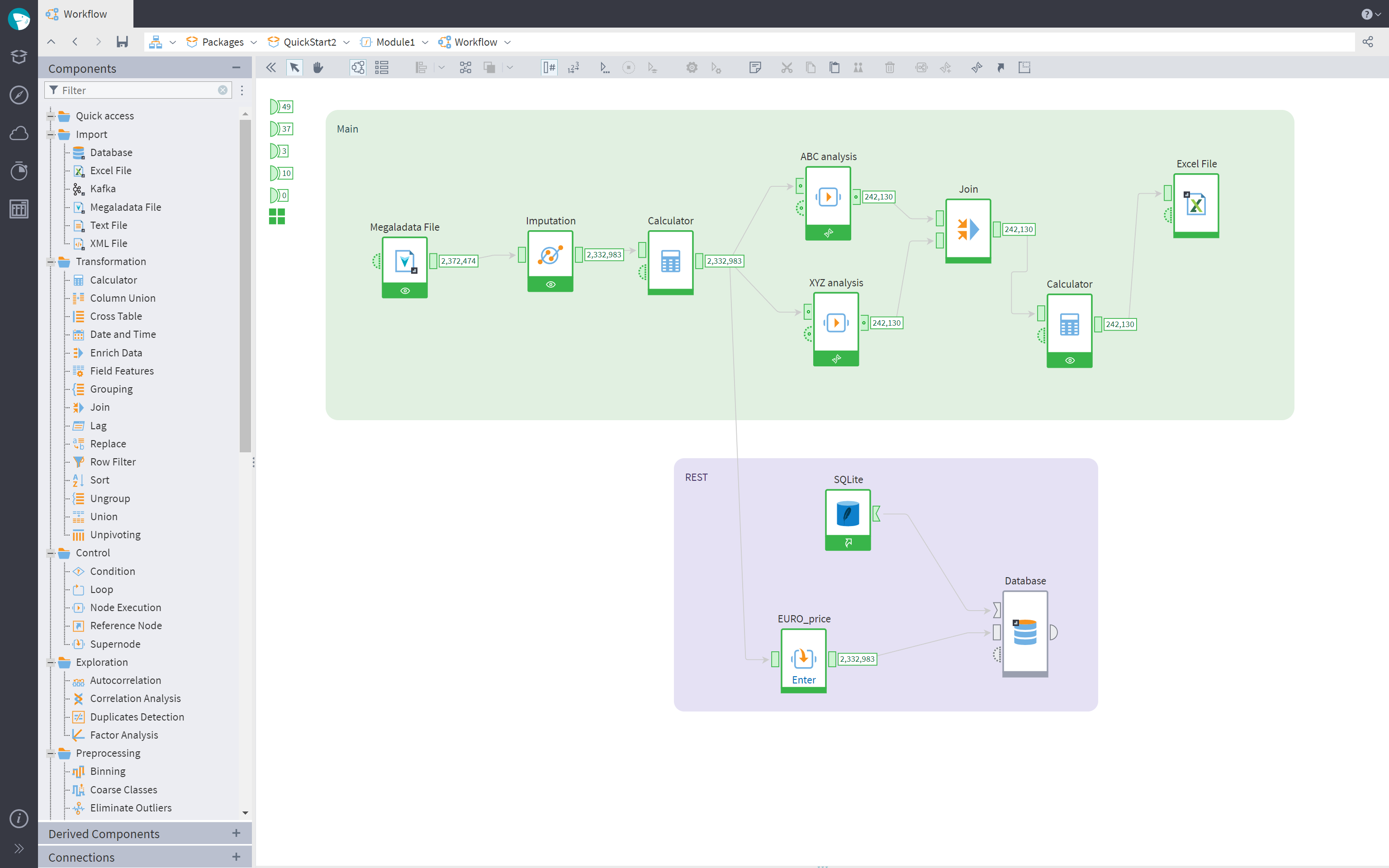
In the workflow’s context menu, the command “Deactivate all” can now deactivate all workflow nodes including those inside the nesting supernodes (and the connections nesting in the supernodes). A similar command has been added to the context menu on the Connections page. In the supernodes’ menu, an entry “Deactivate all subnodes” has been added — it is active when a supernode has the status “Execution”. If the option is enabled, all the nodes of the supernode get deactivated, as well as all connections in the supernode.
When comments are added, moved, or resized, they will now not get beyond the workflow borders.
When a component is dragged to the workflow area, auto-linking of ports will apply to the upper port only. For all the other ports (for example, for control variables), links will not be formed automatically.
All the nodes and comments added to the workflow area in any manner will be aligned with the coordinate grid (8 pixel grid size). The alignment also takes place upon collapsing/expanding supernodes.
For the components Import from XML file, XML Extraction, SOAP request, and Tree to Table, it is now possible to generate compound field names as well as compound field captions. You can choose the corresponding option in the configuration wizards of the nodes, specifying the separator to be used in a compound name.
For export from visualizers in the server editions, the destination file on the disk should be explicitly specified. The system remembers the latest folder to which export was performed before. In the desktop editions under Windows, the destination file for export from visualizers needs to be selected first. Then, the data will be exported (it used to be vice versa). If you cancel the export operation, a file with the name specified and a zero size will remain on the disk.
In the server editions, the files in the File Storage can be inserted to the same directory from which they were copied. In this case, the word "copy" with a dash and the index will be added to the file name (e.g., sales—copy.txt, sales—copy (2).txt, sales—copy (3).txt).
In the MacOS hotkey tooltips, the modifiers Ctrl, Shift, and Alt are displayed as the standard MacOS symbols: ⌘, ⇧, and ⌥.
In the desktop editions of Megaladata, the application scale can be changed using combinations Ctrl+0, Ctrl+-, and Ctrl+=, as well as the commands of the "Appearance" group in the application's menu
Megaladata Integrator and Publishing of Packages
Some optional attributes were added to the element settings of the Megaladata Integrator configuration file:
shutdownTimeout: sets the timeout for shutting down Megaladata Integrator (in seconds). If there are active requests when shutting down Megaladata Integrator, the system will wait for the timeout to expire before forced disconnection from Megaladata Server. During the timeout new requests are not accepted. The default timeout is 30 seconds. However, if IIS has its own timeout, processes will be terminated when the shorter of the two timeouts expires.maxConcurrentRequests: if the attribute has a positive value, the maximum number of parallelly processed requests will be limited by this value. There is no limitation by default. When the limit is reached, all the subsequent requests will be sent to the queue. If a new request is made when maximum queue length (requestQueueLimit) is already reached, the request will be terminated immediately with error 503 Service Unavailable. The limitation on the number of simultaneous requests does not apply to receiving openapi/index.html pages, REST help pages, and OpenAPI or WSDL documents. Setting amaxConcurrentRequestslimit slightly reduces the request processing speed (When tested with a very simple workflow, the speed fell from 3400 to 3300 requests per sec.).requestQueueLimit: maximum queue length (0 by default). If themaxConcurrentRequestsnumber is not set, therequestQueueLimitattribute will simply be ignored.
If the HTTP connection passing the request to Megaladata Integrator is lost, the process of activating a published workflow node will be cancelled. The process cancellation also takes place when Megaladata Integrator shuts down (after the shutdownTimeout expires). If the Megaladata Integrator process has emergency termination (e.g., through SIGKILL or Windows Task Manager), Megaladata Server will continue execution of packages started with Integrator.
Captions of fields and ports were added to published metadata of Megaladata Integrator; this will improve the schemes' readability. We have added description for paths, parameters, and properties to the generated OpenAPI document, based on the captions of nodes, ports, and fields. The documentation gets added if the caption is not empty and not the same as the field/port name.
When publishing a node with Data in Tree Form ports, it is now possible to exclude the root node of the tree from Megaladata Integrator requests and responses. In the data tree input and output ports' wizards, there is a new option "Skip root node upon publishing". Excluding the root node of the tree from requests and responses allows users to create an arbitrary request/response scheme.
To the Administration section, we have added a new server parameter - Web services change check period, set to one minute by default. The parameter defines the frequency of checking the PublishedPackages.cfg file for changes. If the file has changed, the new list of published packages will be read from it.
ASP.NET Core 8.0 is required now to use Megaladata Integrator. (It used to be ASP.NET Core 6.0.)
Logging
We have enabled logging of changes of any administration parameters, including LDAP parameters and OpenID. When a password (in LDAP parameters) or a client's secret (in OpenID parameters) is changed, eight * characters will be written to the log instead of the real password/secret.
Here is an example of a log record:
We have added logging of a package draft creation/closure, changing rights to access shared folders, and changing a package publication.
The information about creating, deleting, reconfiguring, starting, and finishing jobs in the Scheduler will also be logged now (along with the status: completed, cancelled, or error).
In the Administration section, a new logging parameter was added — Log package name for node. If this parameter is set to true, the name of the package to which the node belongs will be logged along with the activated node's GUID. Determining a package name is a lengthy operation, so the parameter is set to false by default.
Performance
Operation of components Union and Join was optimized. A Loop node configured for a supernode where such nodes have a lot of inter-field links is now almost seven times faster.
In server editions, downloading a large file from the File Storage became faster by about 17%. The data gets written right to the file, which ensures economic memory use.
The functioning of the Row Filter component was also optimized. With different conditions and datasets, the node activates from 1.3 to 4 times faster.
Export of rows to SQLite for an in-memory database is now 40-45% faster, tested on various datasets.
Processing of long node chains has become faster due to the optimized node-to-node data requests. In large workflows, it results in up to 50% higher processing speed.
Miscellaneous
Ubuntu 24.04 LTS has been added to the list of base docker images for Megaladata Server.
We have also optimized parsing of XSD schemas that have an element with a lot of child elements and attributes in the root, with references to this element elsewhere in the schema set through the element ref. As a result, configuring XML file import nodes and SOAP Request nodes in wizards and running those nodes consumes less memory.
See also

Megaladata at e-Logi Fest 2026

How Low-Code is evolving ETL
In 2026, you cannot scroll LinkedIn for five minutes without finding a post declaring "ETL is dead, ELT and AI have replaced it." It sounds compelling. It is also wrong.

Megaladata at Plug and Play Armenia Batch 3 Expo
On July 9, 2026, Megaladata took part in the Plug and Play Armenia Batch 3 Expo, the graduation event closing out the three-month International Pre-Acceleration Program in Armenia.
About Megaladata
Megaladata is a low code platform for advanced analytics
A solution for a wide range of business problems that require processing large volumes of data, implementing complex logic, and applying machine learning methods.
GET STARTED!
It's free